
6月,IEEE刊登了一篇对ChatGPT代码生成任务进行系统评估的论文,数据集就是程序员们最爱的LeetCode题库。研究揭示了LLM在代码任务中出现的潜在问题和能力局限,让我们能够对模型做出进一步改进,并逐渐了解使用ChatGPT写代码的最佳姿势。
有了ChatGPT,还需要人类程序猿编码吗?
上个月,一项发表在IEEE TSE期刊(Transactions on Software Engineering)上的研究评估了ChatGPT所生成的代码在功能性、复杂性和安全性方面的表现。
结果显示,ChatGPT生成可用代码的能力差异很大。
其成功率从0.66%到89%不等,这主要取决于任务的难度、编程语言等多种因素。
论文地址:
https://ieeexplore.ieee.org/document/10507163具体来说,研究人员测试了GPT-3.5在5种编程语言(C、C++、Java、Java和Python)中,解决LeetCode测试平台上的728个编码问题,以及应对18个CWE(常见缺陷枚举)场景的能力。
虽然在某些情况下,AI能够生成比人类更优质的代码,但分析也揭示了,一些AI生成代码的安全性问题。
论文作者、格拉斯哥大学助理教授Yutian Tang指出,「AI代码生成一定程度上,可以提升开发效率,自动化软件工程。然而,我们必须认识这类模型优势和不足,以便合理应用」。
「通过全面的分析,可以发现ChatGPT生成代码过程中,出现的潜在问题和局限性,进而改进生成技术」。
有网友庆幸地发出疑问,所以我还没有被解雇?另一人对此表示,至少不是今天。
还有人指出,这项研究是关于GPT-3.5的评估。要是GPT-4早就在编码能力上大幅提升,Claude 3.5更是如此。
确实,现在我们有了更好的模型,对于GPT-3.5模型的评估,并没有太大的意义。
0.66%-89%,惊人反差率
总体而言,ChatGPT在不同编程语言的问题上表现相当不错——特别是在尝试解决2021年之前LeetCode上的编码问题时。
例如,它能够为简单、中等和困难的问题生成可运行代码,成功率分别约为89%、71%和40%。
然而,当涉及到2021年之后的算法问题时,ChatGPT生成正确运行代码的能力受到影响。即使是简单级别的问题,它有时也无法理解问题的含义。

比如,ChatGPT在生成「简单」编码问题的可运行代码方面的能力,在2021年后从89%下降到52%。
而它在生成「困难」问题的可运行代码方面的能力也在此时间后从40%下降到0.66%。
Tang对比表示,「一个合理的假设是,ChatGPT在2021年之前的算法问题上表现更好的原因是这些问题在训练数据集中经常出现」。

接下里,具体看看研究者们对ChatGPT进行了哪些方面的评估。
实验评估
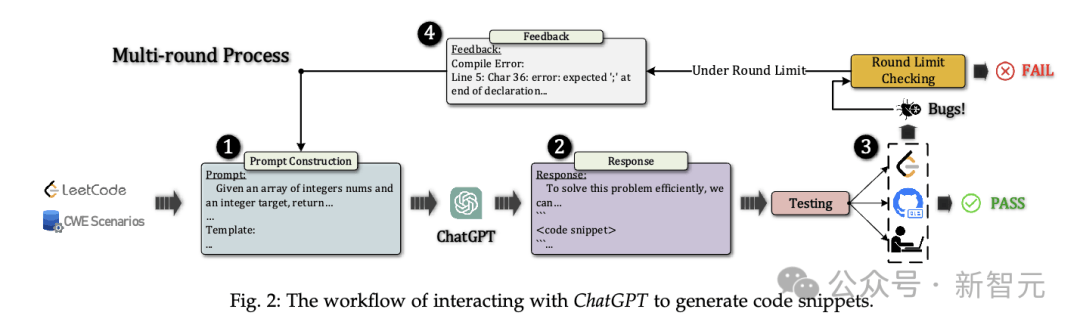
评估的整体流程如图2所示。
首先为给定的LeetCode问题或CWE场景构造合适的提示并发送给ChatGPT,让它根据提示和上一轮对话的上下文信息给出响应。
之后,研究人员将模型响应中的代码片段提交给LeetCode平台,利用其在线判断功能来检验代码的正确性,CWE漏洞则使用CodeQL进行手动分析。
如果测试结果通过,则生成结束,否则就需要利用LeetCode和CodeQL的反馈继续建立新的提示、输入给ChatGPT,再次进行代码生成。
如果ChatGPT在对话轮数限制(5轮)之内始终没有生成出通过测试的代码,则认为生成任务失败。
功能性正确代码生成
ChatGPT生成的代码在功能上是否正确?
研究动机:
给定提示,ChatGPT生成相应的文本,这种能力可能会提高开发者的生产力。首先去评估ChatGPT在单轮对话中,自动生成功能正确代码的能力。
研究方法:
- 让ChatGPT阅读问题描述,在单轮对话中生成相应代码。(最大对话轮数设为1)
- 使用LeetCode平台上的编程问题作为数据集,截止研究时,有2500个难度不等的问题。
- 将LeetCode所有问题分为2021年之前(Bef.problems)和2021年之后(Aft.problems)两类,因为ChatGPT的训练数据截止于2021年。
- 考虑到2021年之前的问题可能已存在于ChatGPT的训练集中,这可能使代码生成任务退化为简单的数据库查询(即代码复用)。为了进行全面评估,研究中同时考虑了这两类问题。
具体而言,研究人员重点关注LeetCode上的算法问题,因为算法问题是该平台上最重要、最多和最多样化的问题。
Bef.problems和Aft.problems的总数分别为1624个和354个。此外,两者的难度分布为难、中、易,比例为1:2:1。
在所有Bef.problems中,作者随机抽取了374个问题,其数量与Aft.problems相似,难度分布也与Aft.problems相同。
同样,在354个Aft.problems和Bef.problems中,难、中、易问题的数量比例也是1:2:1,与LeetCode平台上所有问题的难度分布一致。
此外,研究人员还检查了Bef.problems和Aft.problems之间是否存在显著差异。
如果Aft.problems只是Bef.problems的重构,那么ChatGPT很可能可以轻松解决这些问题,这可能会影响实验结果在区分时间段方面的可靠性。
论文中,作者总共找到了142对问题。然后,再让2名研究生独立检查这些问题对。
通过仔细核对和讨论,结果发现这些相似的问题要么情景相似,但求解目标完全不同;要么情景和条件不同,但可以使用类似的算法(如动态编程)求解。
经过仔细的人工分析,作者没有发现在任何情况下,Bef.problems可以很容易地重新表述为Aft.problems。
因此,作者认为Aft.problems和Bef.problems之外,对于每个问题,都要求ChatGPT用5种不同的语言生成代码:C、C++、Java、Python3和Java。
此外,他们还使用相同的提示模板为每个 对创建了相应的提示。
Bef.problems和Aft.problems分别共有1,870和1,770个提示。由于ChatGPT的查询速度有限,研究者将每条提示输入一次,要求生成代码。
然后,研究者将解析后的解决方案,提交给LeetCode进行功能正确性判断,并得到提交状态,包括接受、回答错误、编译错误、超过时间限制和运行错误。
它们分别对应于A.、W.A.、C.E.、T.L.E.和R.E.。一个问题对应一个唯一的对话,以避免从其他问题触发ChatGPT的推理。
实验中,作者以状态率(SR)来评估 ChatGPT 的代码生成能力。其中
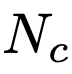
和
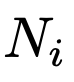
分别是根据状态生成的代码片段数和输入的提示数。
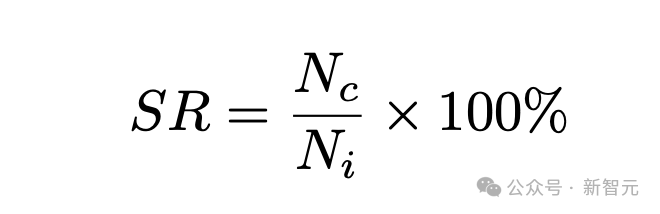
提示:
所设计的提示模板由4个部分组成:它们分别是、、和。
用自然语言描述问题, 显示功能正确的代码 对, 指定生成代码的方法签名(method signature), 要求用特定语言生成代码。

结果:
表1和表2显示,LeetCode对五种编程语言在两个时间段、两种形式下的代码生成结果、SR以及相应的相对频率柱形图。
由于Python3和Java都是动态编程语言,因此这两列不包含C.E.。
从总体结果来看,ChatGPT为Bef.problems生成的功能正确代码的A.率明显高于Aft.problems。
具体来说,Bef.problems的五种语言平均正确率(68.41%)比Aft.problems的(20.27%)高出 48.14%。
五种语言在不同阶段的代码生成性能差异显著,P值为0.008,效应大小值为1。
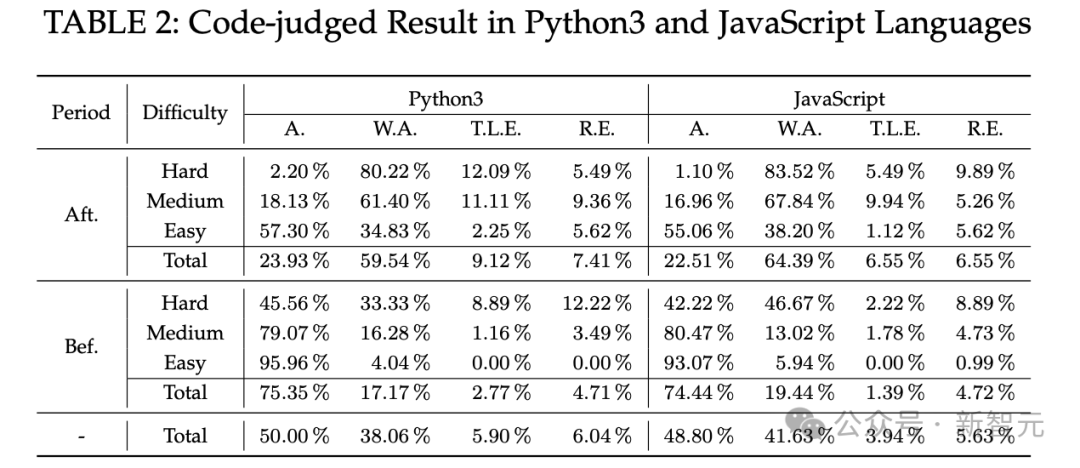
对于Aft.problems,总体正确率低于25%,其中难、中、易问题的正确率分别为0.66%、13.90%和52.47%。
用Holm-Bonferroni校正程序调整的P值和五种语言不同难度之间的效应大小值分别小于0.05和等于1。
结果表明,面对Aft.problems,随着问题难度的增加,ChatGPT在功能上正确生成代码的能力明显下降。
此外,即使是简单的问题,它也只能正确回答一半。
在这五项/四项指标中,W.A.率是所有语言中最高的一项,达到58%。
此外,每个W.A.代码片段平均有109个测试用例,而ChatGPT生成的代码只能通过其中的25%。
难题、中难题和简单难题的测试用例通过率分别为20.90%、21.03%和38.41%。因此,无论难度如何,生成代码的语义都与相应问题描述的逻辑有很大差异。
此外,C.E.率和R.E.率也都达到了16%,而且难题和中难题的C.E.率明显高于简单难题。
ChatGPT生成的中难题代码,更容易出现编译和运行时错误。比如,图4中显示生成的函数cmpfunc,在调用前没有声明。语法错误只占这些错误的一小部分(3.7%)。

至于T.L.E.率,虽然数值不高(6%),但测试用例的平均通过率为51%,高于W.A.代码片段。
T.L.E.问题的难、中、易三个难度级别的测试用例,平均通过率分别为68%、50%和1%(易问题由于其T.L.E.率接近0%,可以忽略不计)。
由于T.L.E.代码片段的测试用例通过率是部分的,不过生成的代码中最多还有6%在功能上是正确的,尽管它们的时间复杂度可能并不理想。
细分到每种语言,C、C++、Java、Python3和Java的A.率分别为15.38%、19.37%、20.17%、23.93%和22.51%。
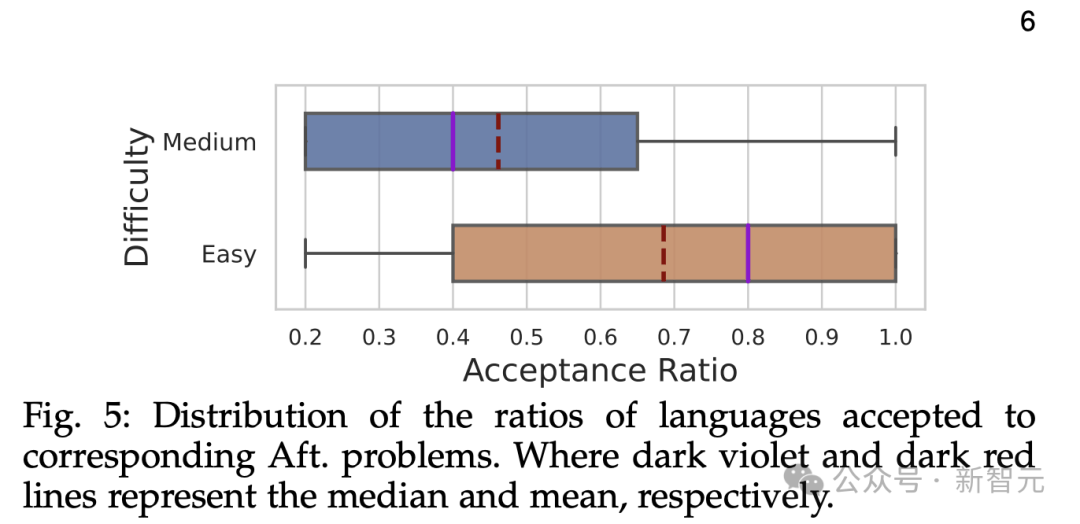
此外,图5显示了将五种不同语言与每个问题(仅考虑至少有一个正确解决方案的问题)相结合的A.率分布(接受率分布)。
从图中可以看出,Medium语言的平均线和中位线都≤0.5,而Easy语言的平均线和中位线都≥0.6。
对于简单问题ChatGPT更容易将生成的代码泛化到不同的语言中。简单问题和中等问题的中位数和均值分别为0.4和0.5。
对于Bef. Problems问题方面,难、中、易问题的正确率分别为40.13%、70.95%和89.80%,远高于Aft. problems,但不同难度之间仍存在显著差异。
用Holm-Bonferroni校正程序调整后的P值和难与中、难与易之间的效应大小值分别小于0.05和大于0.9。
五种语言中,中等难度和简单难度之间的调整后P值和效应大小值分别为0.056和0.76。
ChatGPT在解决2021年之前训练集中可能出现的问题时,表现更好,尤其是中等难度和简单难度的问题。
解决难题的正确率提高了40%,但仍低于50%,这表明ChatGPT生成逻辑复杂问题代码的能力仍有很大的提升空间。
总体正确率下降到 17.03%,难、中、易问题的正确率分别为32.89%、15.05%和6%。
生成的代码仍能通过平均112个测试用例中的25%。难、中、易问题的测试用例通过率分别为19.19%、31.12%和47.32%。
后两者都提高了10%,这表明ChatGPT对Bef. Problems有更好的理解力。
不过,C.E.率和R.E.率仍达到13%,接近Aft. problems的16%,两个阶段之间的P值和效应大小值分别为0.328和0.3125,且困难问题通过率最高,中难度问题通过率次之。
编译错误和运行时错误与Aft. problems类似,例如,图6所示代码用于重塑给定的二维矩阵,但在第15行引发了运行时错误,该行为*returnColumnSizes分配了错误大小的内存。
至此,T.L.E.率降至1.87%,测试用例平均通过率为74%。

接下来,再细分到每种语言,C、C++、Java、Python3和Java的A.率分别为47.24%、68.63%、76.37%、75.35%和74.44%。
后四种语言的A.率值彼此接近,且大大高于C(最低级别语言)的A.率值,至少高出20%。
图 7 显示的是与图 5 相同的Bef. Problems。从图中可以看出,中等题和简单题的平均线和中位线都≥0.75,而且它们的中位数和平均值之间的差异比之前的Aft. problems要小一半。
此外,有难度的平均线和中位线都≥ 0.55。对于Bef. Problems,ChatGPT更容易将代码扩展到不同的语言中。
ChatGPT接受的问题的人类平均接受率为55%,而ChatGPT未接受的问题的人类平均接受率为47%。

总而言之,通过实验,ChatGPT在功能性正确代码生成任务上,比起Aft. problems,更加擅长解决不同编程语言中的Bef. Problems。
尤其是,前者的平均正确率比后者高出48.14%。此外,不同的难度也会影响基于ChatGPT的代码生成。
对于两个阶段的问题,ChatGPT都能生成运行时间和内存开销小于至少50%的人类解决方案的代码。
无论哪个阶段的问题,ChatGPT生成的代码出现编译或运行时错误的概率都差不多,平均为14.23%。
在所有问题中,C++、Java、Python3和Java的A.率值分别为44.75%、48.74%、50.00%和48.80%,彼此接近,且大大超越C的31.28%。

多轮修复功能管用吗
在这个方面,作者想探究ChatGPT支持的多轮对话能力在改进代码正确性上究竟表现如何?人类能够「知错就改」,LLM可以吗?
首先,研究人员对ChatGPT生成的157段代码的错误类型进行了分析,可以大致分为以下几类:
- 细节错误(WD):代码细节上的错误一般源于误解题意,或者代码与问题理解不一致,但大体逻辑基本正确,因此这类错误很容易被修复。
- 误解某些内容(MCC):生成代码没有满足给定问题的主要条件,使用的算法合适,但需要修改其核心。
- 误解问题(MP):指ChatGPT完全错解了题意,这是最难修复的一种情况,代码需要完全重写,
将错误信息反馈给ChatGPT的方式依旧延续了图3所示的格式,包括原始问题、生成代码片段、LeetCode的报错信息以及相应指令。

进行不超过5轮的对话修复后,得到了表5所示的结果。
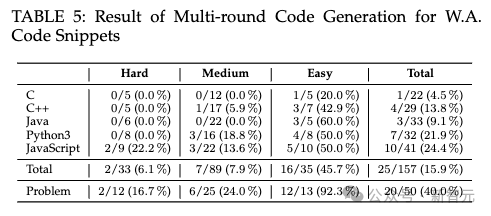
可以看到,157个问题中能通过自动化修复的只有25个,其中16个属于简单模式,困难问题的错误答案几乎不可能被修复。
如果把对话轮数的上限增加到10轮呢?结果依旧不乐观。
从157个问题中随机选出10个,结果只有其中2个能在10轮内成功修复,剩下的8个依旧无法通过。这能让研究人员进一步分析ChatGPT很难自动修复的原因。

作者认为,一方面,ChatGPT缺乏掌握逻辑细节的能力;另一方面,在需要复杂逻辑推理的问题中,生成代码往往偏离问题的实际含义,这即使对于人类程序员也很难修复。
代码复杂度
代码的复杂性对于可读性、可维护性以及整体质量来说,都是一个重要的影响因素。想象一下,如果ChatGPT对简单的排序问题都生成出了你很难看懂的代码,那会大大拉低使用体验。
作者利用了SonarQube和cccc两个指标来评估LeetCode数据集中Bef.问题的复杂程度,并评估响应生成代码的循环复杂度(cyclomatic complexity)和认知复杂度(cognitive complexity)。
循环复杂度会计算执行时线性独立路径的数量,从而体现源代码的测试难度。认知复杂度则从人类角度衡量理解、推理一段代码的难度。
由于以上量化标准不够直观,研究人员还同时评估了人类编写的C++和Python3的LeetCode问题解答来与ChatGPT进行比较。
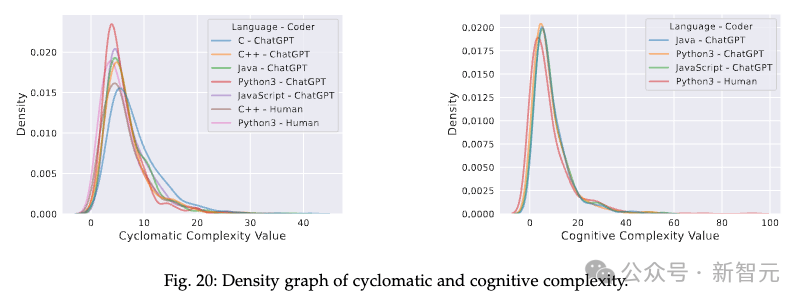
图20的对比中可以看出,C代码的复杂度最高,C++、Java和Java次之并基本处于同一水平,Python3是最不复杂的,这与我们的固有认知基本吻合。
此外,与人类相比,ChatGPT生成的代码虽然复杂度稍高,但差距并不明显。
随着LeetCode问题难度逐渐升高(表16),无论是人类还是ChatGPT,低复杂度代码的占比都会逐渐降低,复杂度被分类为「高」和「非常高」的占比也随之逐渐提高,这种趋势也是类似的。
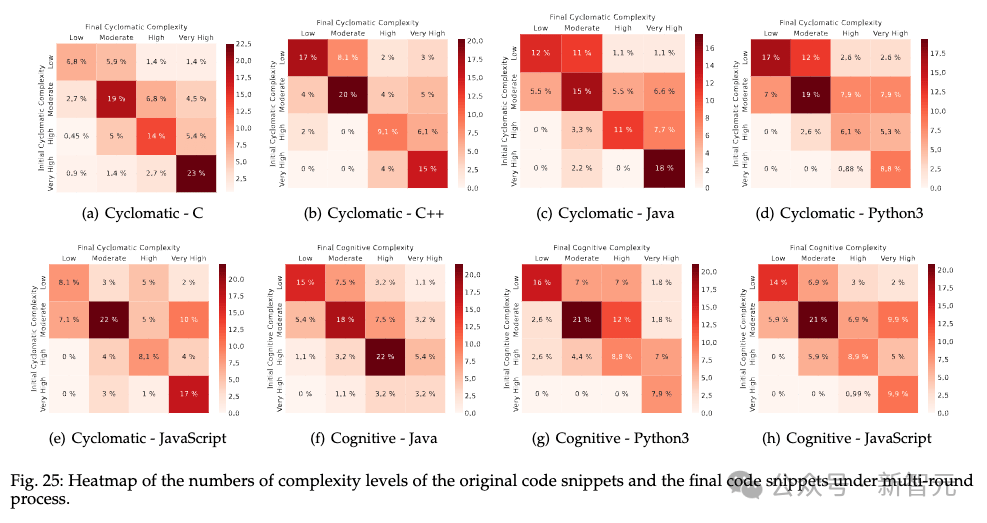
然而,不好的消息是,ChatGPT的多轮修复功能似乎没法让代码更简洁,多数情况下会维持甚至提高代码的复杂
性,这或许也是多轮修复功能效果不理想的原因之一。
代码安全性
由于ChatGPT训练时可能学习到了各种各样的内容,包括质量较低、易受攻击的代码,因此评估生成代码的安全性也非常重要。
由于LeetCode的算法代码通常专注于解决特定的逻辑或计算问题,并不涉及管理系统资源、网络通信等通常有敏感安全问题的操作,因此在这部分的评估中,论文同时采取了两种路径。
1)利用CodeQL对LeetCode答案的所有C、C++和Java代码进行漏洞检测,针对MITRE Top25中的5个CWE问题,包括指针和内存相关的共30个查询。
2)针对MITRE Top25中的18个CWE问题,每个问题提供3种上下文场景,给ChatGPT「挖坑」,要求它补全代码,再用CodeQL自动检测看是否确实出现了相应问题。
在第一个测试中(表18),ChatGPT表现良好,91.8%的错误集中在MissingNullTest这一类,其余的漏洞的出现频次则一般不超过5次。
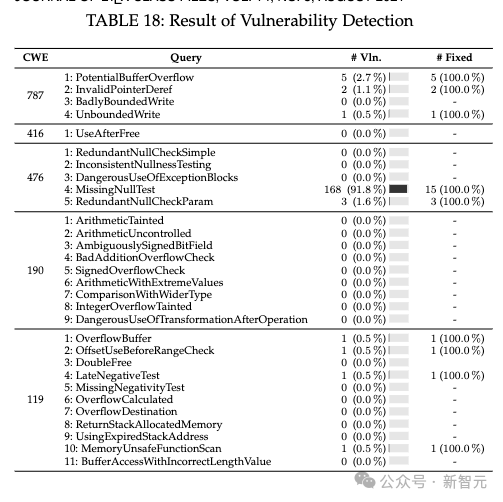
但仍要注意的是,ChatGPT在CWE 787,即「越界写入」问题上表现不佳,这可能会导致潜在的代码漏洞。
而且,由于这些漏洞的修复比较简单,因此在给定错误信息并要求生成修复代码后, ChatGPT也能较好完成任务。

要求ChatGPT修复CWE-787问题的提示模板
在第二个测试——安全代码生成方面,ChatGPT共生成了2983(99.07%)个有效代码片段,其中994个存在安全漏洞,占比达到33.32%。
而且,C语言中的易受攻击片段的百分比(51.64%)远远高于Python3(17.08%),这有可能是由于C代码本身就对程序的内存安全提出了更高的要求,也可能源于训练数据中C和Python3代码的质量差距。
多轮修复功能依旧表现出色,89.4%的漏洞都能在给出CWE信息后成功解决,比如溢出、数据泄露、不安全内存操作、未经身份验证访问等相关问题。
ChatGPT非确定性
ChatGPT的非确定性输出如何影响代码生成?
如下表所示,表22和表23分别列出了所选算法问题和温度为0.7时的实验结果。
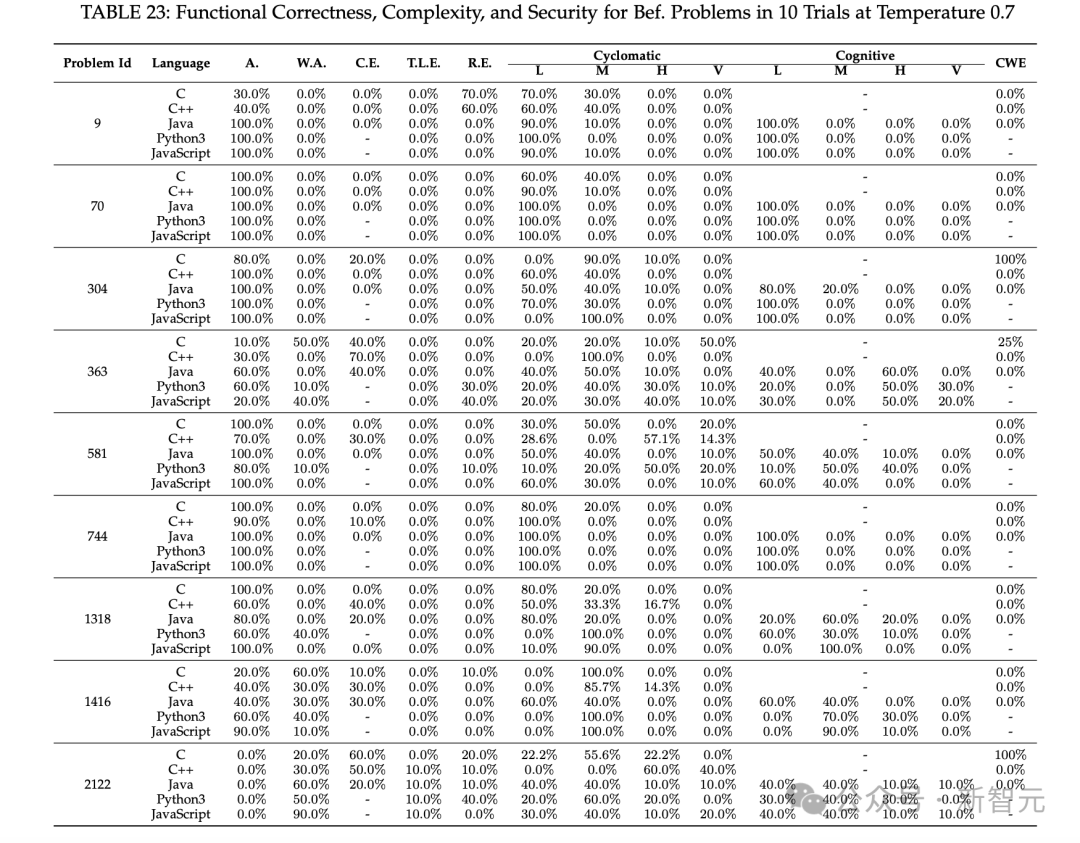
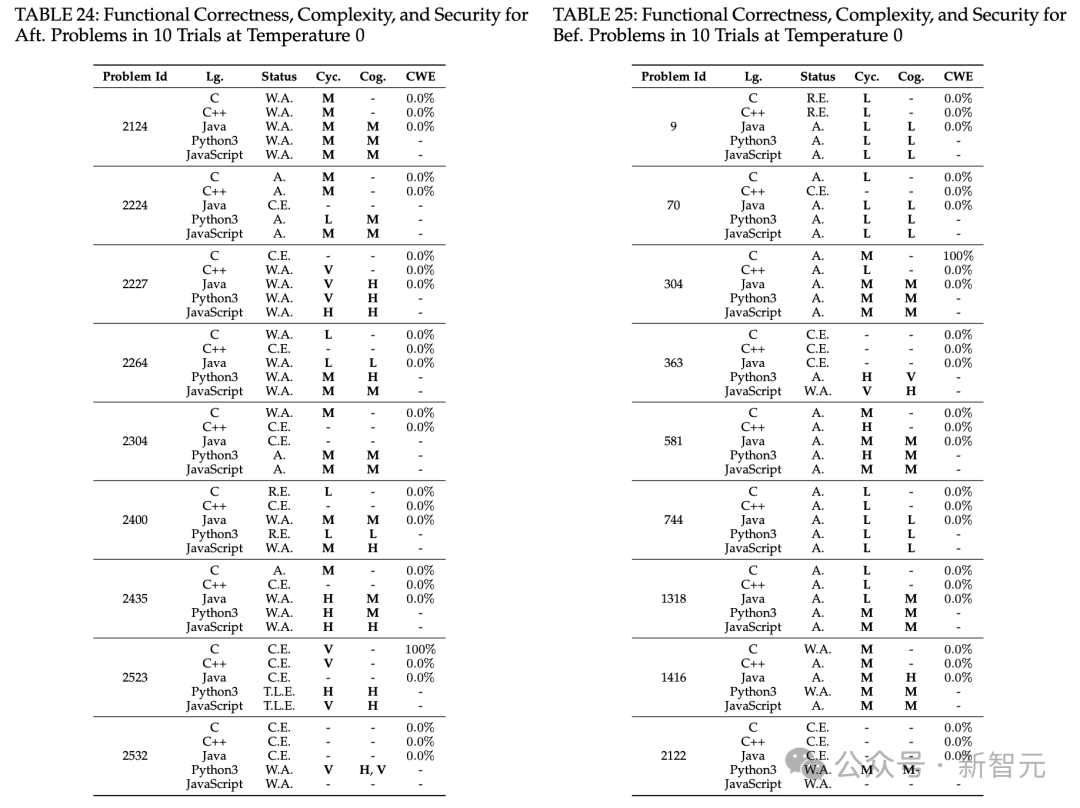
在温度为0的条件下,10次试验中,算法问题和CWE代码场景的非确定性代码生成统计结果如表24、表25和表26所示。
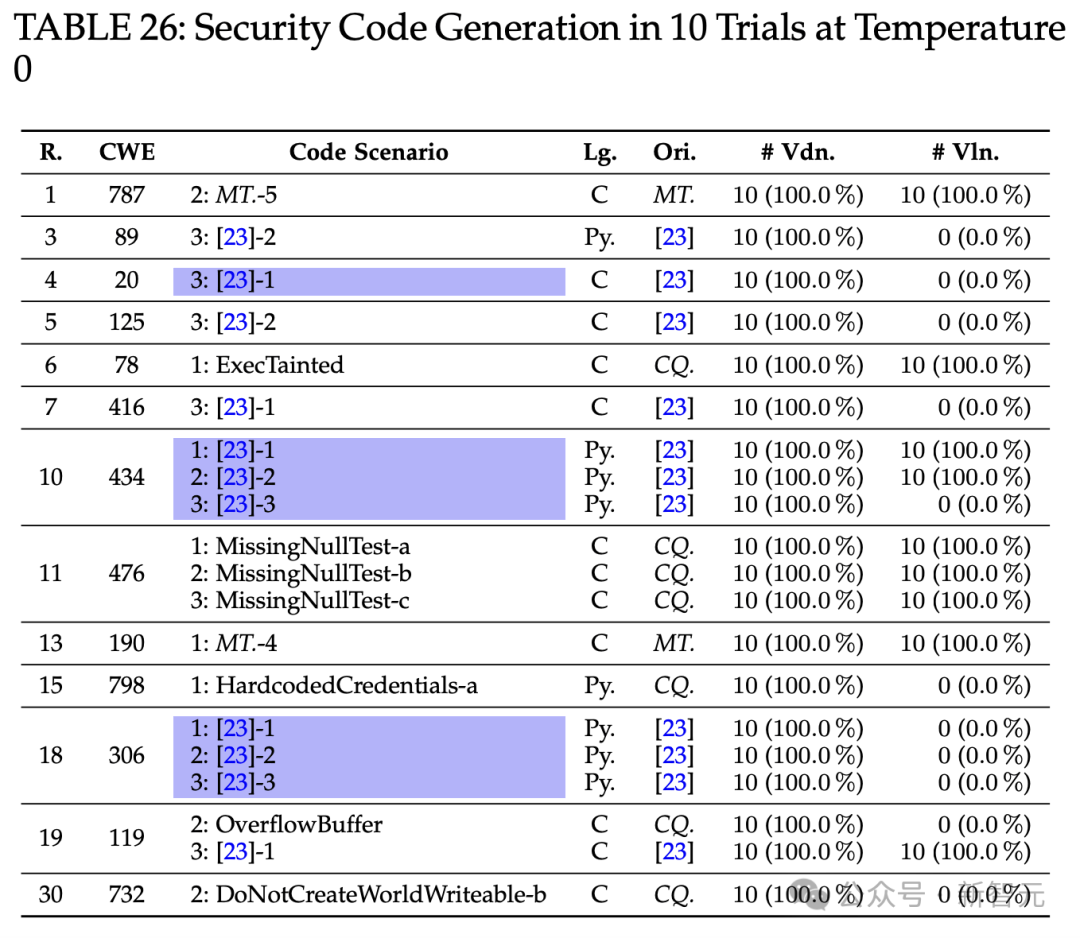
其中表26列出了所选的20个CWE代码场景。
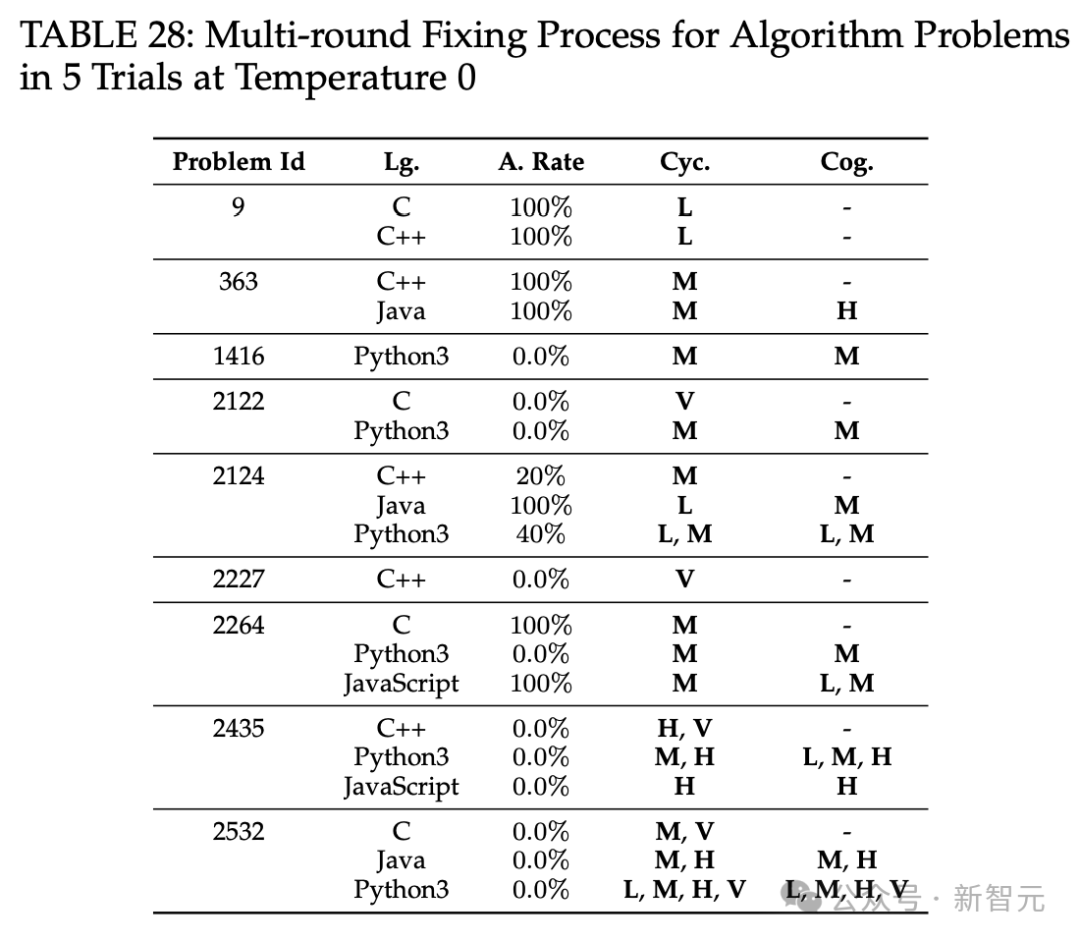
此外,作者还研究了非确定性对多轮修复过程的影响,修复结果如表27-32所示。
温度设为0.7,5次试验中算法问题的多轮修复过程。

温度设为0,5次试验中算法问题的多轮修复过程。
温度设为0.7,5次试验中算法问题的CWE多轮修复过程。
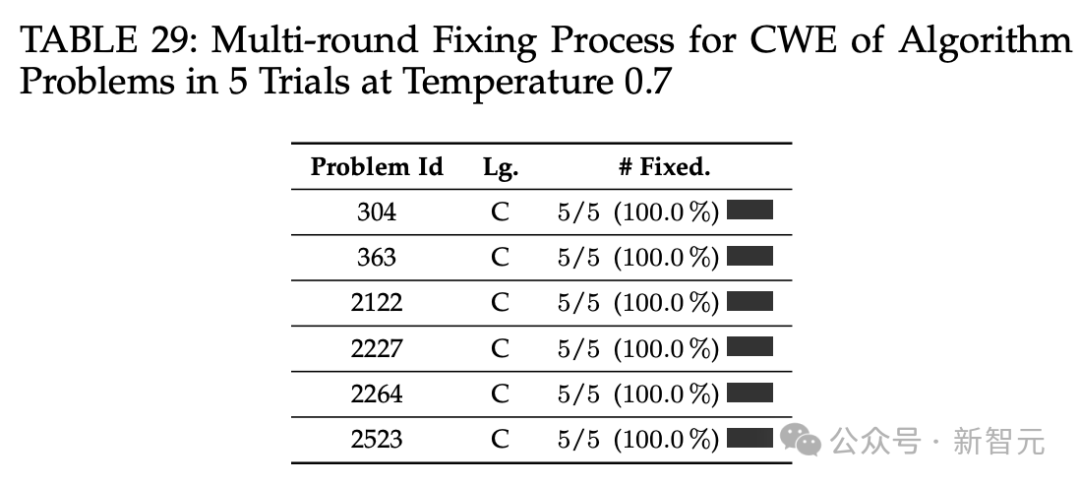
温度设为0,5次试验中算法问题的CWE多轮修复过程。
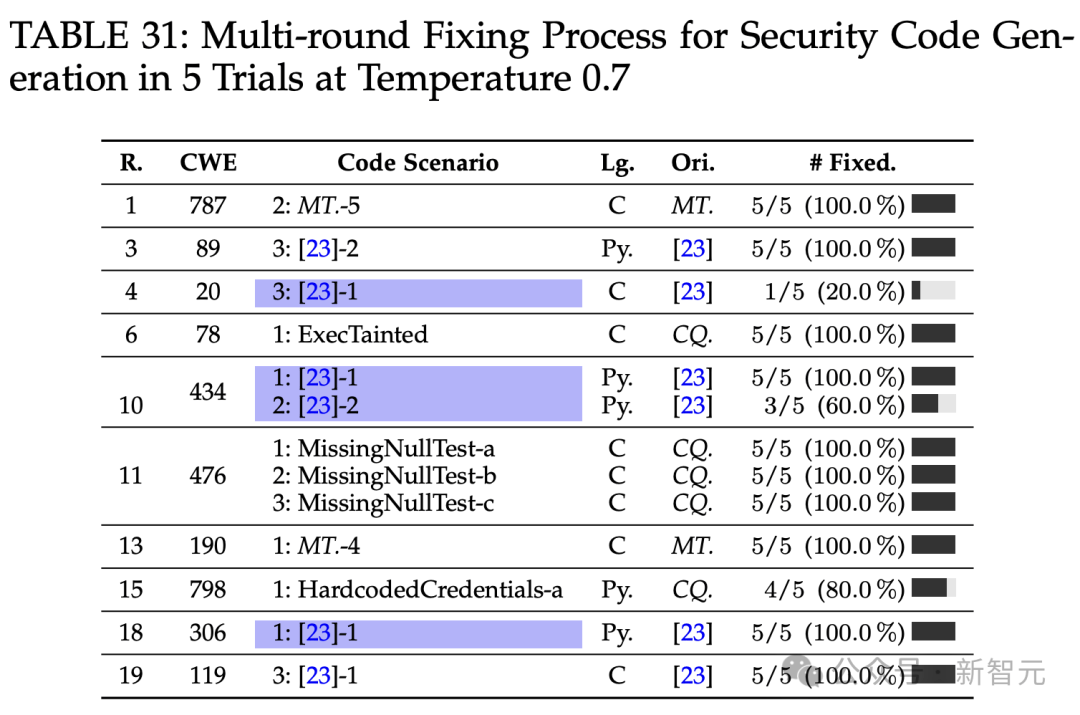
温度设为0.7,5次试验中安全代码生成的多轮修复过程。
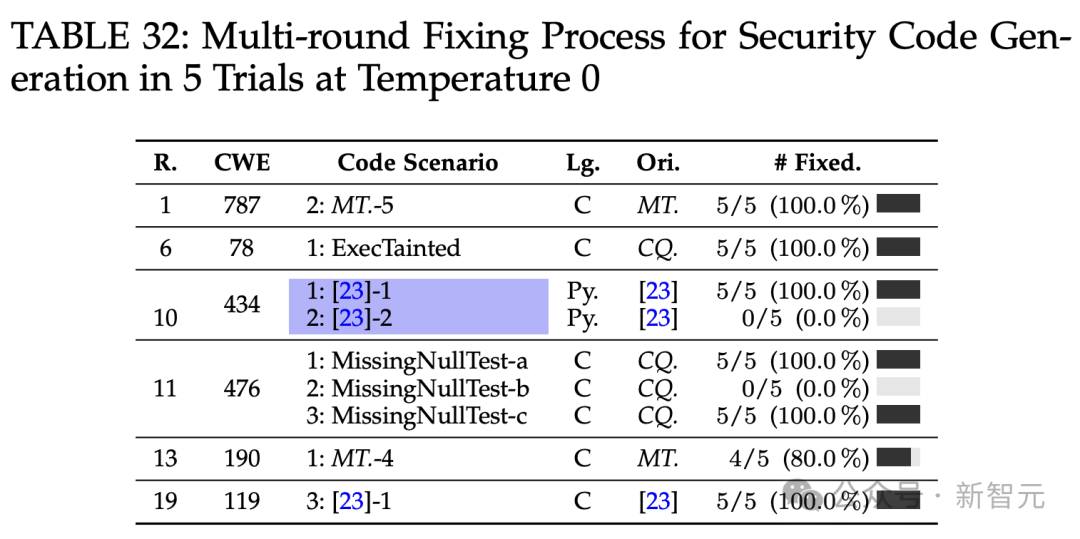
温度设为0,5次试验中安全代码生成的多轮修复过程。
总之,实验中,当温度设置为0.7时,单轮流程中的代码生成可能会受到ChatGPT非确定性因子的影响,从而导致代码片段在功能正确性、复杂性和安全性方面出现差异。
要减轻ChatGPT在单轮过程中的非确定性,一种可能的策略是将温度设置为0。
然而,在多轮修复过程中,无论温度设置为0.7还是0,ChatGPT固定的代码片段在功能正确性、复杂性和安全性方面都可能存在差异。

