文 | 下海fallsea,作者 | 胡不知
2025年12月24日,平安夜的硅谷没有温情。当大多数人沉浸在节日氛围中时,AI算力圈传来一则足以改写行业格局的消息:英伟达宣布以200亿美元现金,与曾喊出“终结GPU霸权”的AI芯片初创公司Groq达成技术许可协议。
更耐人寻味的是交易的特殊结构:这不是一次正式收购,Groq将继续独立运营,但创始人Jonathan Ross、总裁Sunny Madra等核心团队成员全部加入英伟达;英伟达获得Groq几乎所有核心技术资产,仅排除GroqCloud云计算业务。200亿美元的对价,是Groq三个月前69亿美元估值的2.9倍,这种“估值倒挂”的技术许可,在科技行业史上极为罕见。
“这不是收购,却胜似收购。”伯恩斯坦分析师Stacy Rasgon一针见血地指出,“本质是英伟达用金钱换时间,把最危险的颠覆者变成自己人,同时规避反垄断审查的障眼法。”
这场交易的背后,是AI产业的历史性转折——从集中式模型训练,全面迈入规模化推理落地的新阶段。推理市场正以年复合增长率65%的速度扩张,预计2025年规模突破400亿美元,2028年更是将达到1500亿美元。而英伟达的GPU霸权,在推理赛道正遭遇前所未有的挑战:谷歌TPU凭借成本优势抢食大客户,AMD MI300X拿下微软40亿美元订单,中国的华为昇腾在本土市场份额已飙升至28%。
曾被视为“GPU终结者”的Groq,为何最终选择与英伟达联手?200亿美元的天价交易,能否帮英伟达守住算力王座?这场“招安”背后,更折射出AI芯片行业创新者的集体困境:当技术颠覆者撞上巨头的生态壁垒,除了被收购,是否还有第二条生路?
颠覆者Groq
Groq的诞生,从一开始就带着“挑战权威”的基因。2016年,谷歌TPU核心开发者Jonathan Ross带着团队7名核心成员集体出走,创立了Groq。这位高中辍学的技术天才,在谷歌期间深度参与了AlphaGo等重大AI项目,亲眼见证了传统GPU在AI推理场景的致命短板——高延迟、低能效、数据传输瓶颈。
“GPU的架构从根源上就不适合推理任务。”Ross在2023年的行业峰会上直言,“它就像一个万能的瑞士军刀,什么都能做,但在需要精准、高效的推理场景里,效率低得惊人。”带着这种认知,Ross团队立志打造一款专为推理优化的专用芯片,这就是后来的LPU(语言处理单元)。
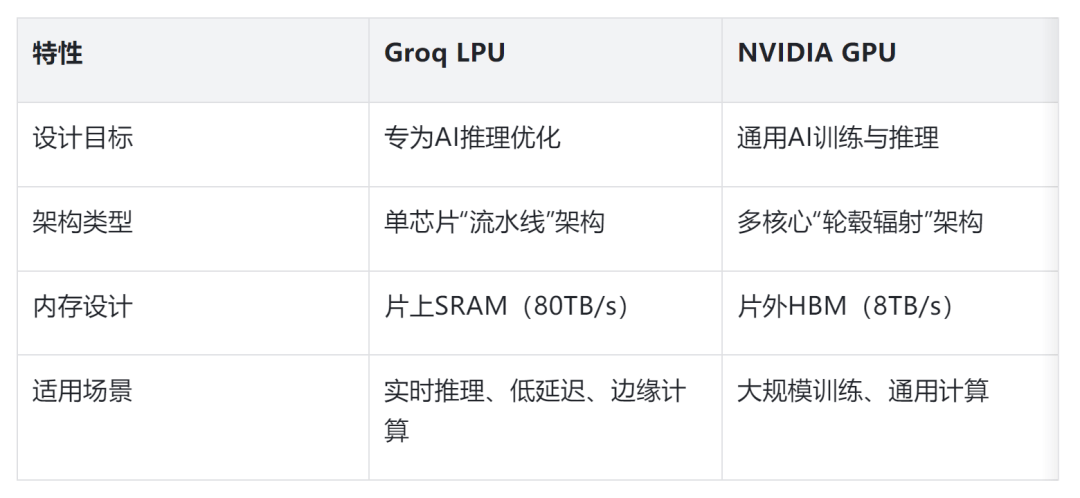
Groq的LPU,本质上是对AI芯片架构的一次重构。与英伟达GPU的“轮毂辐射”架构不同,LPU采用了独特的“可编程流水线”设计——数据像在传送带上一样,依次经过各个处理单元,全程无冗余传输,彻底解决了GPU的“内存墙”问题。
这种架构带来了三个革命性优势:一是极致的低延迟,首token响应时间仅0.22秒,在实时对话、自动驾驶等场景中,比GPU快5-18倍;二是超高能效比,功耗仅300-500W,是英伟达H100(700W)的三分之二,能效比更是GPU的10倍以上;三是确定性计算,每个执行步骤都能精确到时钟周期,这对企业级AI应用的稳定性至关重要。
最关键的是内存设计。LPU集成了数百MB的SRAM作为主权重存储,而非GPU的片外HBM内存,内存带宽高达80TB/s,是HBM的10倍。在处理Llama 2-70B这类大模型时,LPU的吞吐量能达到241 tokens/秒,是其他云服务商的2倍以上。独立测试数据显示,在相同推理任务下,Groq的解决方案能将算力成本降低至GPU的三分之一。
颠覆性的技术让Groq成为资本的宠儿。从2017年首轮1000万美元融资,到2021年C轮融资后估值突破10亿美元成为独角兽,再到2025年9月E轮融资后估值飙升至69亿美元,Groq的估值在短短一年间(2024年8月-2025年9月)暴涨146%,累计融资超30亿美元。
市场层面,Groq也快速打开局面。它不仅服务了超过200万开发者,还拿下了多个重量级客户:与Meta合作运行Llama 3.1大语言模型,与沙特阿美达成15亿美元协议建设全球最大AI推理数据中心,成为加拿大贝尔主权AI网络的独家推理提供商。在部分细分场景,Groq已经开始替代GPU——比如在实时客服、智能驾驶感知等对延迟敏感的领域,多家企业反馈“切换到Groq后,用户体验和运营成本都有质的提升”。
但Groq的崛起始终面临一个致命短板:生态壁垒。英伟达的霸权从来不是靠硬件算力,而是靠历经二十余年打造的CUDA生态——全球2000万开发者、10万+应用、几乎所有主流AI框架,都深度绑定CUDA。企业要切换到Groq的LPU,需要重构70%以上的推理代码,时间和人力成本高到难以承受。2024年,Groq曾试图深化与Meta的合作,但最终因“适配成本过高”不了了之——Meta的LLaMA模型深度依赖CUDA,切换到LPU需要6个月的开发时间,而Meta根本等不起。
这就是Groq的悖论:有颠覆GPU的技术,却没有打破CUDA生态的能力。这种困境,也是所有AI芯片初创公司的共同枷锁。
英伟达的霸权焦虑
对英伟达而言,2025年是关键的转折点。尽管公司股价年内累计涨幅超35%,截至2025年10月持有现金及短期投资达606亿美元,但隐藏在光鲜数据背后的,是日益加剧的竞争压力。尤其是在推理市场,英伟达的GPU霸权正在被多方蚕食。
谷歌TPU是英伟达最直接的威胁。作为Groq创始人Ross的老东家,谷歌在AI推理领域的布局更早、更深。2025年推出的TPU v7“Ironwood”,性能接近英伟达Blackwell架构,更关键的是,谷歌凭借自研芯片+云服务的一体化优势,能提供30%-40%的成本优势。
更让英伟达紧张的是,谷歌TPU正在从自用走向对外销售。Apple、Anthropic等巨头已经开始用TPU训练大模型,部分云服务商也开始采购TPU替代GPU。“谷歌的策略很明确,用成本优势抢食对价格敏感的推理市场,逐步瓦解英伟达的客户基础。”业内分析师指出。
AMD的崛起则从中端市场撕开了口子。2025年,AMD MI300X获得微软Azure 40亿美元订单,市场份额从2024年的10%提升至15%,预计全年AI芯片营收将超50亿美元,同比增长120%。AMD的优势在于兼容性——MI300X能兼容CUDA生态,企业切换成本极低,同时价格比同性能GPU低20%-30%。
除了微软,AMD还拿下了亚马逊、谷歌等云服务商的部分订单。“客户都在搞‘去英伟达依赖’,即使不全面替代,也会采购AMD芯片作为备份,这本身就分流了英伟达的市场份额。”一位云服务商内部人士透露。
在中国市场,英伟达的处境更为艰难。受出口管制影响,英伟达的高端芯片无法进入中国,而华为昇腾趁机崛起,市场份额从2023年的15%飙升至2025年的28%,超过AMD成为中国市场第二,英伟达的份额则从70%暴跌至54%。
更关键的是,中国市场形成了“大厂自研+芯云一体”的独特模式。华为、百度、阿里等巨头都在自研AI芯片,优先满足自身云业务和AI应用需求,几乎不采购国产初创公司的芯片,更遑论英伟达。这种模式进一步挤压了英伟达的生存空间,也让中国成为全球AI芯片竞争的“独立战场”。
除了竞争压力,英伟达GPU本身在推理场景也存在天生短板。随着AI应用从实验室走向产业,低延迟、高能效、低成本成为核心需求——自动驾驶需要毫秒级的实时感知,智能客服需要即时的对话响应,工业质检需要边缘端的低功耗推理,这些场景都不是GPU的强项。
“GPU是为训练而生的通用计算芯片,推理只是‘副业’。”行业专家解释,“训练追求极致算力,不在乎成本和延迟;但推理追求效率,每一分成本、每一毫秒延迟都影响商业价值。英伟达要守住推理市场,必须补全低延迟、高能效的短板。”
而Groq的LPU,恰好精准命中了这些痛点。这也是英伟达愿意花200亿美元“招安”Groq的核心原因——与其让Groq成为竞争对手的“武器”,不如将其纳入自己的体系,补全推理端的技术短板。
200亿美元的“障眼法”与真实图谋
这场被包装成“技术许可协议”的交易,实则是英伟达精心设计的“变相收购”。200亿美元的天价,买的不只是Groq的技术,更是核心人才、市场渠道,以及规避反垄断审查的“安全通行证”。
根据官方公告,这是一项“非独家技术许可协议”,Groq将继续独立运营。但深入分析会发现,这只是规避反垄断审查的“障眼法”。首先,Groq的核心资产几乎全部转让——技术专利、研发团队、客户资源都归英伟达所有,仅保留GroqCloud业务;其次,灵魂人物Jonathan Ross及核心团队全部加入英伟达,失去核心人才的Groq,独立运营的意义已大打折扣。
“如果是正式收购,必然会触发严格的反垄断调查。”伯恩斯坦分析师Stacy Rasgon指出,“用技术许可的形式,既能拿到核心资产和人才,又能维持‘竞争存在’的表面假象,这是近年来科技巨头的常用手段。”微软、谷歌等公司都曾用类似模式吸纳初创企业的核心资产,规避监管风险。
200亿美元的对价,是Groq当前69亿美元估值的2.9倍,看似天价,实则合理。对英伟达而言,这200亿美元买的是三个“确定性”:一是补全推理端技术短板的确定性,避免自主研发的时间成本和失败风险;二是消除潜在竞争对手的确定性,将Groq这个“威胁”转化为自己的优势;三是巩固生态壁垒的确定性,将LPU技术融入CUDA生态,进一步提升客户切换成本。
从财务角度看,200亿美元对英伟达而言压力不大。截至2025年10月,英伟达持有现金及短期投资达606亿美元,200亿美元仅占33%。更重要的是,这笔投资的潜在收益巨大——如果Groq的技术能帮助英伟达在推理市场维持70%以上的份额,按2028年1500亿美元的市场规模计算,每年能带来超1000亿美元的营收,200亿美元的投入不到两年就能收回成本。
英伟达的真实图谋,是通过这次交易实现“人才+技术+渠道”的三位一体整合。人才方面,Jonathan Ross作为谷歌TPU的核心开发者,对AI推理芯片的架构设计有深刻理解,他的加入能让英伟达的推理架构更贴近市场需求;技术方面,Groq的LPU架构、确定性编译器等核心技术,能直接弥补GPU的短板;渠道方面,Groq的客户资源(如沙特阿美、加拿大贝尔)能帮助英伟达快速拓展推理市场。
“英伟达的战略从来不是单纯卖硬件,而是构建‘硬件+软件+服务’的全栈生态。”业内人士分析,“收购Groq后,英伟达能推出‘GPU(训练)+LPU(推理)’的异构计算解决方案,覆盖从训练到推理的全流程,进一步强化生态壁垒。”
GPU与LPU的“双剑合璧”能否奏效?
这场交易的成败,关键在于英伟达能否成功整合Groq的技术,实现GPU与LPU的优势互补。从架构差异来看,两者具有天然的互补性,而非替代关系。
GPU擅长“并行计算”,能将复杂任务分解为数千个可同时执行的小计算,适合大规模模型训练;而LPU擅长“流水线计算”,数据依次经过处理单元,无冗余传输,适合低延迟、高吞吐量的推理任务。
英伟达的计划,是将LPU整合到自身的“AI工厂”架构中,形成“训练用GPU,推理用LPU”的解决方案。比如,在自动驾驶场景,用GPU训练感知模型,用LPU实现实时推理;在智能客服场景,用GPU训练对话模型,用LPU处理用户的即时请求。
技术整合的最大挑战,在于软件生态的兼容。Groq有自己的GroqWare套件和GroqFlow工具链,而英伟达的核心是CUDA生态。如果两者无法无缝对接,企业客户的切换成本依然很高。
不过,Groq的软件设计理念与英伟达高度契合。GroqWare兼容PyTorch、TensorFlow等主流框架,GroqFlow工具链允许用一行代码导入现有模型,这为整合到CUDA生态提供了基础。英伟达的计划是,将Groq的编译器和工具链融入CUDA平台,让客户能在CUDA生态内直接调用LPU的算力,无需重构代码。
“软件整合成功与否,将决定这次交易的价值。”行业专家指出,“如果能实现无缝兼容,英伟达的生态壁垒会进一步加固;如果整合失败,200亿美元可能会打水漂。”
根据基准测试数据,整合Groq技术后,英伟达的推理解决方案能实现双重优化:一是成本降低,推理成本可降至GPU的三分之一;二是效率提升,延迟可降低至200毫秒以内,部分场景甚至能达到50毫秒。
这种优化能直接推动AI应用的规模化落地。比如,实时对话AI的延迟降低后,能更好地应用于客服、教育等领域;边缘计算的能效提升后,能推动AI在工业质检、智能农业等场景的普及。“推理成本和延迟的降低,是AI从‘实验室走向产业’的关键。”云计算开源产业联盟的报告指出,2026年推理在AI服务器工作负载中的占比将达到70.5%。
AI芯片格局的固化与创新者的宿命
英伟达“招安”Groq的交易,不仅会重塑AI芯片的竞争格局,更会深刻影响整个AI产业的发展轨迹。它既暴露了行业的创新困境,也揭示了未来的发展趋势。
这场交易标志着AI芯片行业进入“整合阶段”。过去5年,类似的故事不断上演:Graphcore融资超10亿美元却难以规模化,Habana被英特尔收购后逐步边缘化,寒武纪在国内靠政务市场勉强支撑。这些“挑战者”要么被巨头收编,要么在生态壁垒前慢慢耗死。
英伟达的这次交易,进一步加剧了这种趋势。当所有有潜力的创新者都被纳入巨头版图,AI芯片市场的“固化”已不可避免。预计到2027年,英伟达的市场份额仍将维持在75-80%,AMD占10-12%,谷歌TPU占8-10%,其他厂商的份额仅剩下2-3%。
“初创公司的生存空间越来越小。”一位AI芯片创业者无奈表示,“要么在技术上找到巨头完全没覆盖的边缘场景,要么就等着被收购。正面挑战巨头的生态壁垒,几乎不可能成功。”
Groq的命运,是AI芯片行业创新者的缩影。它有颠覆GPU的技术,却没有打破CUDA生态的能力。这背后的核心原因,是生态壁垒的“锁定效应”——客户一旦接入CUDA生态,切换成本高达数千万美元,几乎不可能轻易迁移。
这种生态壁垒,比技术和硬件更难逾越。国产GPU厂商也面临同样的困境,尽管投入重金打造兼容CUDA的软件栈,但始终处于“跟随者”的地位。华为昇腾能在国内崛起,很大程度上是因为依托自身的“芯云一体”模式,构建了内部闭环的“小生态”,而非打破了英伟达的生态壁垒。
“创新者的困境不是技术不行,而是生态不行。”业内分析师指出,“未来,AI芯片的竞争不再是单一芯片的比拼,而是‘生态+场景+技术’的综合较量。谁能构建起自己的生态,谁才能真正立足。”
尽管格局固化,但这次交易对AI产业的发展并非全是负面影响。最直接的好处,是推理成本的大幅降低,这将加速AI技术的普及。云计算开源产业联盟的报告显示,通过推理优化技术,长序列生成任务的吞吐量能提升30%-50%,首Token延迟能降低40%-60%。
成本降低后,更多中小企业将有能力部署AI应用,推动AI从“巨头专属”走向“千行百业”。比如,零售行业的实时推荐、医疗行业的辅助诊断、工业行业的预测性维护等场景,都将因为推理成本的降低而加速落地。
同时,LPU的低延迟、高能效特性,将推动AI计算向边缘端迁移。智能交通、工业质检、智能农业等边缘场景的AI应用,将迎来爆发期。“推理技术的进步,是AI赋能实体经济的关键一步。”南开大学金融发展研究院院长田利辉指出,推理芯片将形成云端、边缘、终端三元共存的格局,真正实现“AI赋能千行百业”。
算力战争的终局与新机会
站在AI产业从训练转向推理的关键节点,英伟达与Groq的联手,或许只是算力战争的一个中场插曲。未来3-5年,AI芯片行业将呈现三大趋势,同时也会诞生新的机会。
未来,“GPU+LPU”的异构计算将成为主流。GPU负责训练和复杂计算,LPU等专用芯片负责推理和实时处理,两者协同工作,实现全流程的高效计算。英伟达已经开始推进这一战略,将LPU整合到“AI工厂”架构中,其他厂商也会纷纷跟进。
“异构计算是解决训练与推理需求差异的最佳方案。”行业专家预测,“到2028年,超过80%的AI数据中心都将采用异构计算架构。”
随着数据中心功耗限制日益严格,能效比将成为AI芯片的核心竞争力。谷歌TPU、Groq LPU的崛起,都得益于超高的能效比。未来,芯片厂商的竞争焦点将从“算力高低”转向“每瓦算力多少”,低功耗、高能效的芯片将更受市场欢迎。
为了适应不同场景的需求,“软件定义硬件”将成为新的发展方向。通过软件优化,实现硬件性能的最大化利用,同时降低客户的适配成本。英伟达的CUDA生态、Groq的编译器,都是软件定义硬件的典型案例。未来,软件能力将成为芯片厂商的核心竞争力之一。
尽管巨头垄断了主流市场,但边缘场景和垂直行业仍有新机会。比如,工业物联网的边缘设备需要低功耗AI芯片,医疗行业的诊断设备需要专用推理芯片,这些场景的需求相对小众,但巨头覆盖不足,初创公司仍有生存空间。
“真正的颠覆从来不是从正面进攻,而是从巨头的视线之外生长起来的。”就像当年的AWS没有挑战IBM的大型机,而是从按需付费的云服务切入,最终颠覆了整个IT行业。下一个“Groq”,或许正在某个边缘场景里,悄悄打磨着能打破生态壁垒的技术。
结语
200亿美元“招安”Groq,是英伟达在推理时代保卫算力王座的关键一步。它用金钱换时间,补全了技术短板,消除了潜在威胁,同时规避了反垄断风险,堪称一次教科书级的战略布局。
但这场算力战争远未结束。谷歌TPU的成本优势、AMD的兼容性攻势、中国芯片企业的本土替代,都将继续挑战英伟达的霸权。更重要的是,AI产业的发展永远充满不确定性,新的应用场景、新的技术路线,都可能诞生新的颠覆者。
对整个AI产业而言,这场交易是一把“双刃剑”:它可能加剧巨头垄断,阻碍技术创新;但也可能加速推理技术的普及,推动AI赋能千行百业。最终的走向,取决于英伟达能否平衡商业利益与产业创新,也取决于行业能否诞生新的生态破局者。
站在2025年的时间节点,我们正见证着AI产业的历史性转型。英伟达与Groq的联手,或许只是这个转型过程中的一个注脚。但它清晰地告诉我们:算力战争的本质,从来不是单一芯片的比拼,而是生态、技术与场景的综合较量。在这场没有终点的战争中,只有那些能精准预判趋势、快速补全短板、持续构建生态的企业,才能最终坐稳算力王座。

