IT之家 6 月 8 日消息,苹果机器学习研究中心于当地时间 6 月 6 日发表了一篇研究论文,称现有 AI 模型并不具备真正的思维能力或推理能力,而是依赖于模式匹配与记忆,尤其是对于复杂的任务而言。

苹果研究人员对现有的前沿“大型推理模型”—— 如 OpenAI o3-mini、DeepSeek-R1、Anthropic 的 Claude 3.7 Sonnet Thinking 和谷歌 Gemini Thinking—— 进行了系统评估。
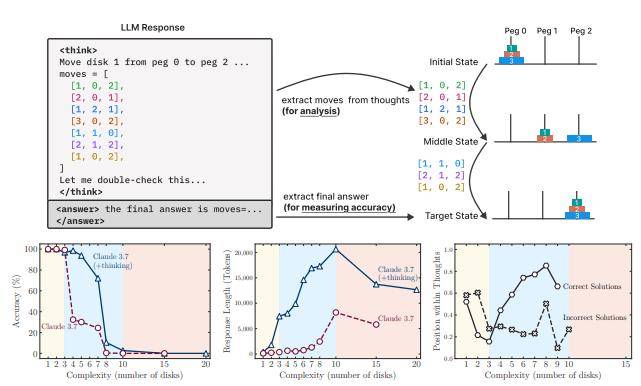
研究发现,尽管这些模型具备生成详细“思考链”的能力,并在中等复杂度任务上表现出优势,但其推理能力存在根本性局限:当问题复杂度超过特定临界点时,模型性能会完全崩溃至“零准确率”。
此外,在模型推理过程中,即使仍有充足的推理算力,它们用于“思考”的 token 数量反而随难度上升而减少,这种现象意味着现有推理方法存在根本局限性。
这篇《思考的幻象:通过问题复杂性的视角理解推理模型的优势与局限》由 Parshin Shojaee 等人撰写。研究表明,当前业界对这些模型的评估主要集中在数学和编程基准测试上,关注最终答案的准确性,但这往往忽略了数据污染问题,也无法提供有关内部推理轨迹结构和质量的洞见。
研究人员采用了一系列可控的解谜环境,允许精确操纵组成复杂性,同时保持逻辑结构的一致性。这使得不仅可以分析最终答案,还可以探究内部推理轨迹,从而更深入地了解这些模型是如何“思考”的。
研究团队提出,模型表现可分为三个阶段:低复杂度任务:传统大模型(IT之家注:如 Claude-3.7 无思维版本)表现更佳;中等复杂度任务:具备思维机制的大型推理模型(LRMs)更占优势;高复杂度任务:两类模型均陷入完全失效状态。
特别是,研究发现 LRMs 在执行精确计算方面存在局限性,无法使用显式算法且跨不同谜题进行推理时表现出不一致性。
总的来说,这项研究不仅质疑了当前基于已建立数学基准的 LRMs 评估范式,还强调了需要更加细致的实验设置来探索这些问题。通过使用可控制的谜题环境,本研究提供了对语言推理模型能力和局限性的深刻见解,并为未来的研究指明了方向。
研究人员表示,“这些发现突出了现有 LRMs 的优点和局限性,引发了关于这些系统推理本质的问题,这对它们的设计和部署具有重要意义。”

