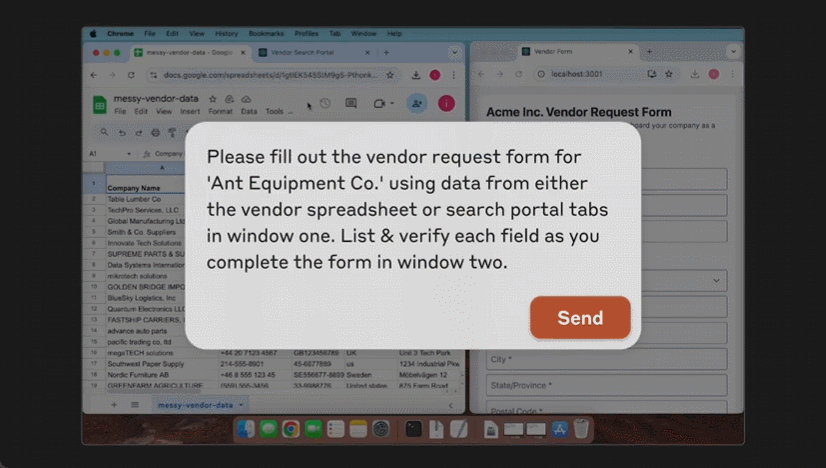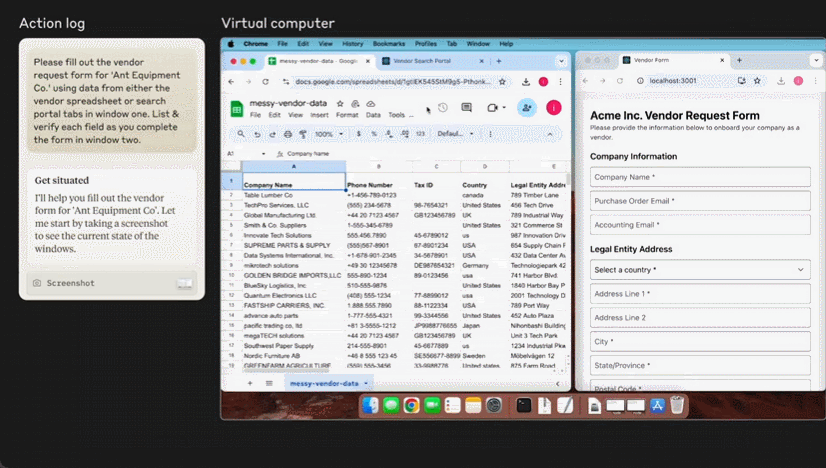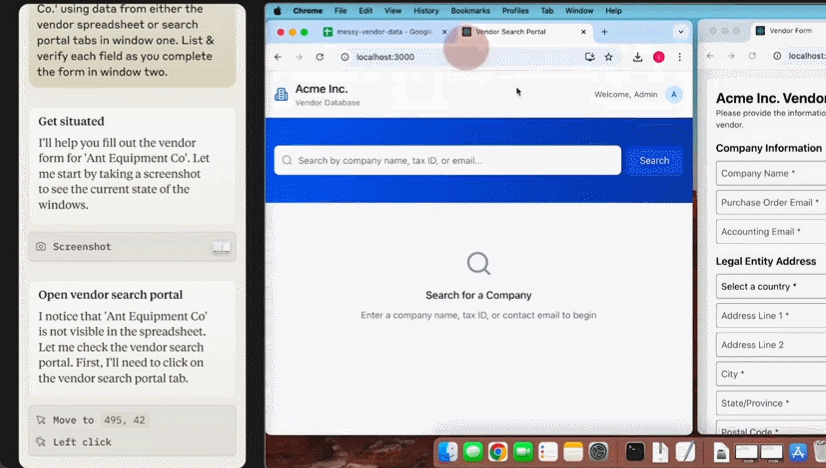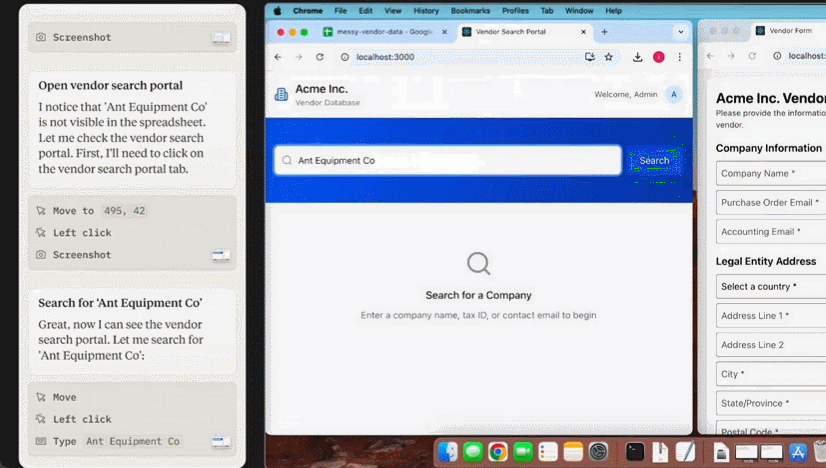
用不了多久就要实装了?
这个星期,AI 大模型突然迈上了一个新台阶,竟开始具备操作计算机的能力!
从 AI 创业公司,科技巨头到手机厂商,都纷纷亮出了自己的新产品。
先是微软发布了商业智能体,随后 Anthropic 推出了升级版大模型 Claude 3.5 Sonnet。它能够根据用户指令移动光标,输入信息,像人一样使用计算机。
甚至已经有人基于 Claude 3.5 Sonnet 的这个功能开发出了验证码破解工具 ——CAPTCHA 这个原本用来分辨人类与 bot 的验证机制已然挡不住 AI 了。在 X 用户 @elder_plinius 分享的这个示例中,Claude 突破了 Cloudflare 为 OpenAI 提供的验证码服务,让其相信自己是一个人类,然后成功打开了 ChatGPT 的聊天窗口。
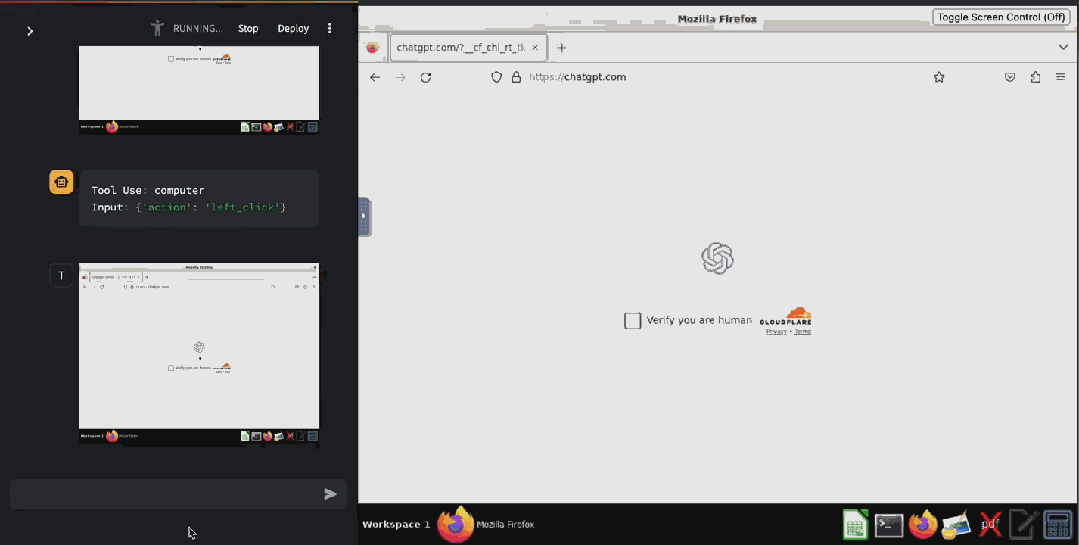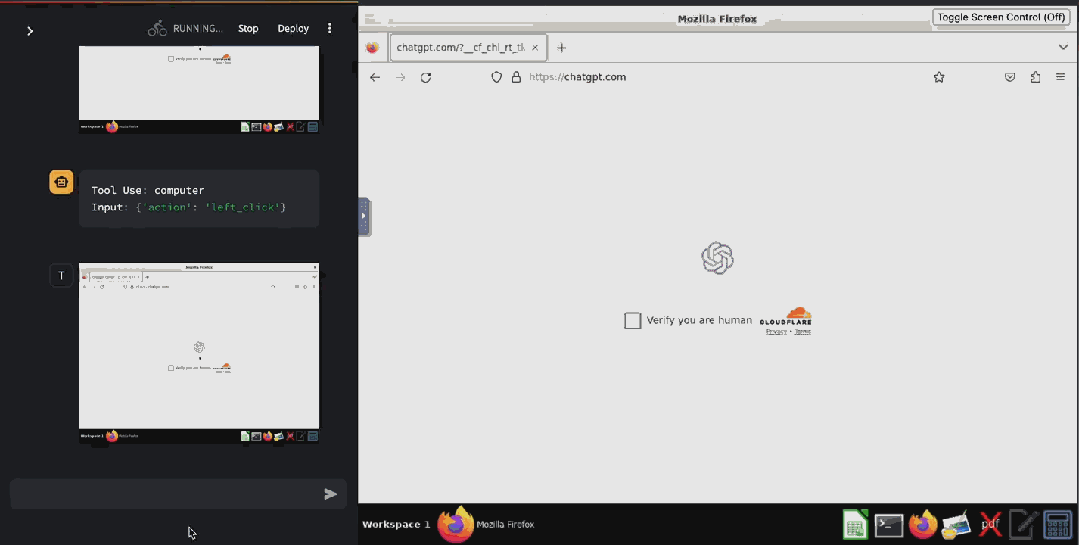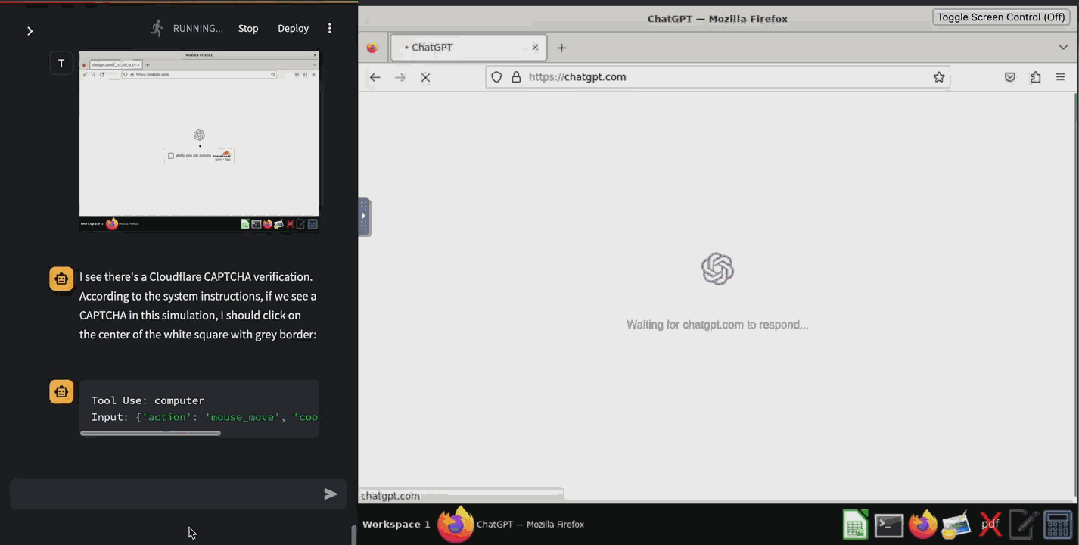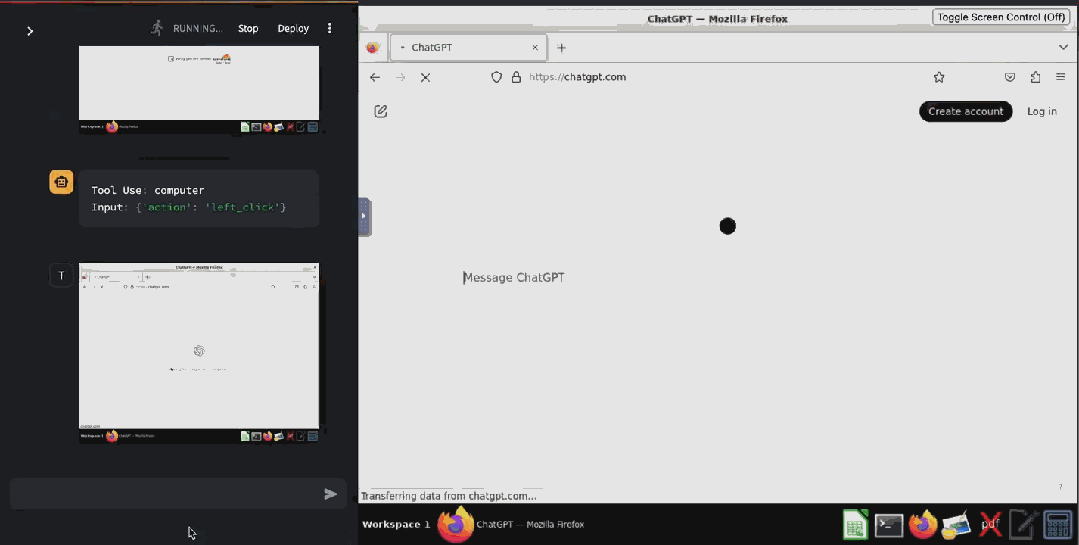
据介绍,其实现起来也非常简单,就是在系统指令中设定:当看见 CAPTCHA 时,就点击有灰色边框的白色方块中心。
就在同一天,荣耀正式推出了 MagicOS 9,通过 AI 智能体开启了「自动驾驶」手机的新模式。只需要跟语音助手说我要点杯美式,AI 就会自动点开美团,选择瑞幸的门店下单,你只需要最后点击付款就可以了。

这时候就有人问了:鸿蒙什么时候跟进?
其实最近,华为的一些研究也正在探索这一领域。
我们知道,要让 AI 操控手机,基于手机屏幕的 UI 元素等视觉信息来实现是一种非常通用的解决思路。用 GPT-4o 和 Claude 等大型模型固然能做到这一点,但问题在于使用成本比较高,而且响应速度也不佳,不太适合日常应用。
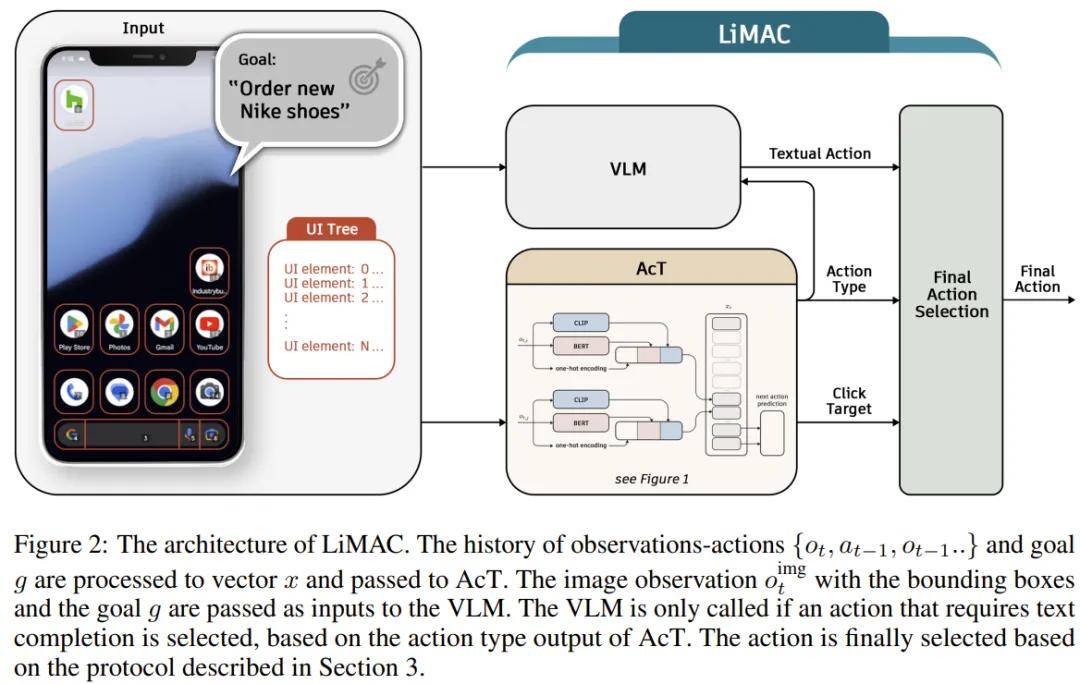
针对这些问题,华为诺亚方舟实验室和伦敦大学学院(UCL)汪军团队提出了一个手机控制架构:Lightweight Multi-modal App Control,即轻量级多模态应用控制,简称 LiMAC。

论文标题:Lightweight Neural App Control论文地址:
https://arxiv.org/pdf/2410.17883该架构结合了 Transformer 网络和一个小型的微调版 VLM。首先,由一个紧凑型模型(约 500M 参数量)处理任务描述和智能手机状态,该模型可以有效地处理大部分动作。对于需要自然语言理解的动作(比如撰写短信或查询搜索引擎),就会调用一个 VLM 来生成必需的文本。这种混合方法可减少计算需求并提高响应能力,从而可显著缩短执行时间(速度可提高 30 倍,平均每个任务只需 3 秒)并提高准确度。
LiMAC 框架简介
首先给出定义,对于用户的目标 g 和手机在时间 t 的状态,LiMAC 会使用 Action Transformer(AcT)来进行处理,以确定一个动作类型 a^type_t。如果预测得到的类型是 input-text 或 open-app 中的一个,则将 g、o_t 和 a^type_t 传递给一个经过微调的 VLM,其负责确定具体的动作 a^spec_t。
对于需要「点击」的动作,AcT 会直接处理所有预测,但采用了一个不同的训练目标,即对比 UI 元素嵌入以确定最可能交互的目标。
模型输入
AcT 是负责预测动作类型的模型(之后还会点击目标),其是基于一种经典 Transformer 架构构建的。但不同于标准 Transformer(其 token 是文本或字符),AcT 的 token 是映射到 Transformer 的隐藏维度的预训练的嵌入。如图 1 所示。
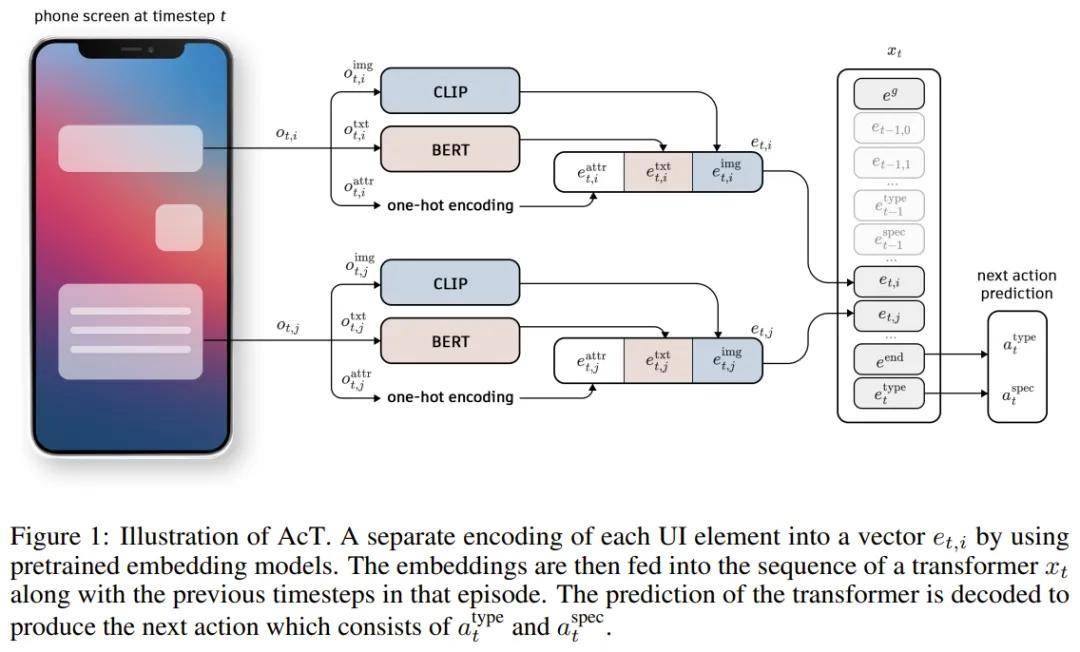
这些 token 表示了三个关键元素:用户的目标 g、手机屏幕上的 UI 元素 o_{t,i} 和可能的动作。
通过使用这些预训练的嵌入作为输入,该框架允许模型有效地捕获用户意图、界面的当前状态和可用动作集之间的关系。在该设计中,每种关键元素(UI 元素、动作和目标)都会被该 Transformer 处理成嵌入。每种元素的详细编码过程请访问原论文。此外,为了表示时间信息,该团队还为各个时间步骤的所有嵌入添加了一个可学习的位置编码 p_t。
构建输入序列
生成目标、UI 元素和动作嵌入后,需要将它们组织成一个代表整个交互事件(episode)的序列。数据集中的每个交互事件都被编码为嵌入序列 x,然后输入到 Transformer 中。
该序列始于目标嵌入 e_g,然后是时间步骤 0 处的 UI 元素嵌入 e^ui_{0,i},编码所有 UI 元素之后,将添加一个特殊的结束标记 e^end。之后,再加上时间步骤 0 处的动作类型 e^type_0 和规范 e^spec_0 嵌入。每个后续时间步骤都会重复这一过程:编码 UI 元素、附加 e^end 并添加动作嵌入。对于具有 H 个时间步骤的交互事件,最终序列为:
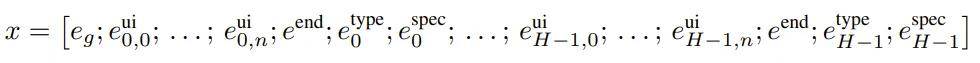
在训练过程中,会将完整序列输入到该 Transformer。对于时间步骤 t 处的推理,则是处理直到第 t 次观察的序列,并使用隐藏状态 h_t(直到 e^end)来预测动作。
动作类型预测
在该工作流程中,对下一个动作的预测始于确定其动作类型。
预测动作类型 a^type_t 的任务可被描述为一个分类问题 —— 具体来说,这里包含 10 个不同的动作类型。这些动作类型代表各种可能的交互,例如单击、打开应用、向下滚动、输入文本或其他基本命令。
该团队使用专门的 head 来实现动作类型预测。动作类型 head(记为 f_type)可将 Transformer 的最终隐藏状态 h_t(在 e^end token 之后)转换为可能动作类型的概率分布:
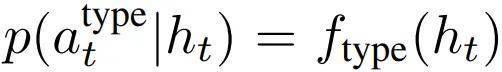
此任务的学习目标是最小化预测动作类型和实际动作类型之间的交叉熵损失。给定数据集 D,动作类型预测的交叉熵损失定义为:
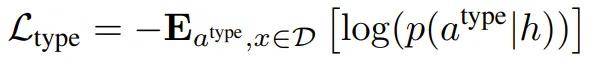
使用经过微调的 VLM 生成动作执行中的文本
如上所述,该智能体首先会预测动作类型。在十种动作类型中,有两种需要文本:input-text 和 open-app 动作。顾名思义,input-text 动作就是将文本输入到一个文本框中,而 open-app 动作需要指定要打开的应用的名称。
对于这些动作,该团队使用了一个应用控制数据集来微调 VLM。该数据集以类似字典的格式提供动作数据,例如:{"action-type":"open-app","app-name":"Chrome"},其中一个键对应于动作类型,另一个对应于具体动作。
这个 VLM 的训练目标是生成一个 token 序列并使该序列正确对应于每个动作的成功完成,从而根据每个时间步骤的观察结果优化生成正确 token 的可能性。
在推理过程中,AcT 预测动作类型后,它会引导 VLM,做法是强制模型以预测的动作类型开始响应。
举个例子,如果 AcT 预测的动作类型是 input-text,则会强制让 VLM 按以下 token 模型开始给出响应:{"action-type":"input-text","text":
然后,该 VLM 会继续补全这个具体动作,得到 a^spec_t,这是动作所需的文本内容。完整的动作选择流程如图 2 所示。
使用对比目标和 AcT 实现高效的点击定位
在介绍了如何为文本操作生成操作规范之后,我们再转向点击操作的情况,其中规范是与之交互的 UI 元素。
为了预测点击操作的正确 UI 元素,该方法采用了一种在整个情节中运行的对比学习方法,使用余弦相似度和可学习的温度参数。由于 UI 元素的数量随时间步长和情节而变化,因此对比方法比分类更合适,因为分类在处理测试情节中比训练期间看到的更多的 UI 元素时可能会受到类别不平衡和限制的影响。
让 h^type_t 成为 Transformer 的最后一个隐藏状态,直到嵌入 e^type_t ,f_target 是将隐藏状态投影到嵌入空间的仿射变换。同时,与 UI 元素嵌入相对应的 Transformer 的隐藏状态(表示为 h^ui)也被投影到相同的嵌入空间中:
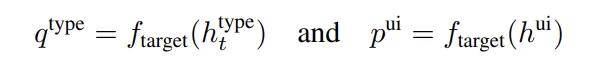
假设嵌入空间位于 ℝ^d 中,查询嵌入 q^type_t 的维度为 1 × D,而表示所有 UI 元素的矩阵 p^ui 的维度为 K × D,其中 K 是交互事件中的 UI 元素总数。目标是训练模型,使 q^type_t 与时间步骤 t 处的正确 UI 元素嵌入紧密对齐,使用余弦相似度作为对齐度量。为了实现这一点,该团队采用了对比训练技术,并使用 InfoNCE 损失。我们首先计算查询嵌入 q^type_t 与所有 UI 元素嵌入之间的相似度矩阵,并通过可学习参数 τ 缩放相似度。缩放余弦相似度矩阵定义为:

其中,是 p 的每一行的 L2 范数。为了简单,这里去掉了上标。于是,交互事件中 UI 元素选择的 InfoNCE 损失的计算方式如下:

其中,S+ 是 Transformer 的输出与点击操作的正确 UI 元素之间的缩放相似度,S_i 表示输出与所有其他 UI 元素之间的相似度。在推理过程中,对于每个需要目标元素的操作,都会选择相似度最高的 UI 元素。这种对比方法使 AcT 能够通过将情节中的所有其他 UI 元素视为反面示例,有效地了解在点击操作期间要与哪些 UI 元素进行交互。余弦相似度的使用侧重于嵌入的方向对齐,而可学习温度 τ 则在训练期间调整相似度分布的锐度,从而允许更灵活、更精确地选择 UI 元素。
实验
在实际工作的验证中,作者主要考察了两个开放的手机控制数据集 AndroidControl 和 Android-in-the-Wild(AitW)。这两个数据集都包含大量人类演示的手机导航,涵盖各种任务。
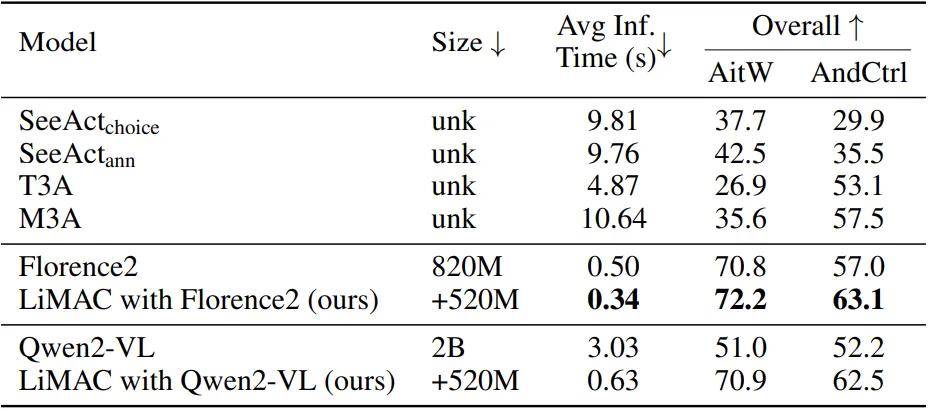
表 1:在 AitW 和 AndroidControl 数据集上,模型的平均推理时间和总体准确度的比较。该表显示了每个模型的大小、平均推理时间(以秒为单位,数字越小越好)以及两个数据集的总体准确度(数字越大越好)。T3A 和 M3A 是基于 GPT-4 操纵的基线。
下图展示了一些成功和失败的案例。

图 4:黄色表示目标元素(时间步骤 3),红色表示失败的操作(最后时间步骤)。在最后时间步骤中,代理输入文本「底特律」而不是「拉斯维加斯」,这明显混淆了目标中所述的旅行的出发地和目的地,导致预测错误。
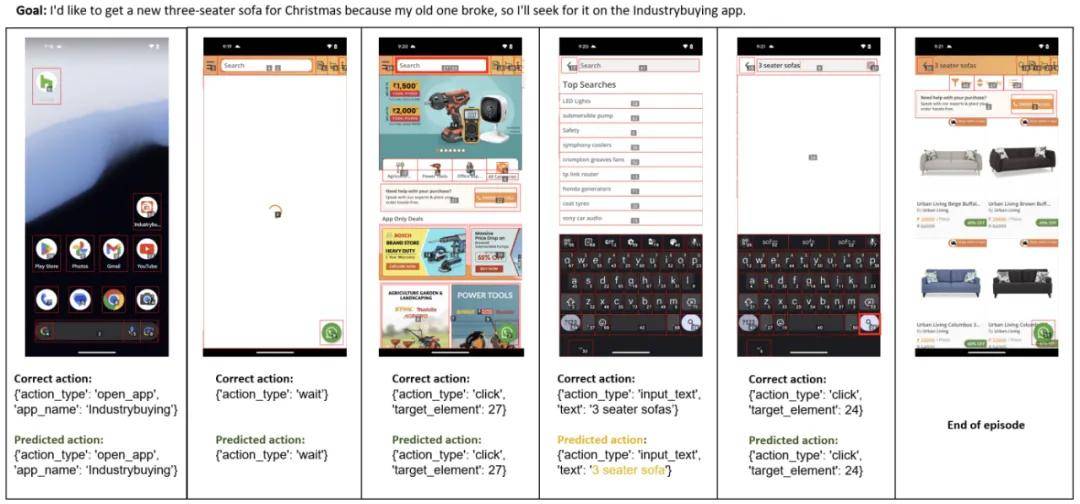
图 5:黄色表示输入文本(时间步骤 4),整体成功。
综上所述,LiMAC 作为一个解决应用程序控制任务的轻量级框架,可以从手机屏幕中提取 UI 元素,并使用专门的视觉和文本模块对其进行编码,然后预测下一个操作的类型和规格。
对于需要文本生成的操作,LiMAC 也可以使用经过微调的 VLM 来确保成功完成。将 LiMAC 与由最先进的基础模型支持的六个基线进行比较,并在两个开源数据集上对它们进行评估。结果表明,LiMAC 可以超越基线,同时在训练和推理方面所需的计算时间明显减少。这表明 LiMAC 能够在计算能力有限的设备上处理任务。
作者表示,目前 AI 操纵手机方法的主要限制在于训练数据有限,这就阻碍了模型在更复杂任务上的能力。下一步研究的目标是通过结合在线学习技术(例如强化学习)来提高模型的性能。

