近日,来自谷歌和苹果的研究表明:AI模型掌握的知识比表现出来的要多得多!这些真实性信息集中在特定的token中,利用这一属性可以显著提高检测LLM错误输出的能力。
大模型的应用历来受幻觉所扰。
这个幻觉可以指代LLM产生的任何类型的错误:事实不准确、偏见、常识推理失败等等。
——是因为大模型学半天白学了吗?并不是。
近日,来自谷歌和苹果的研究表明:AI模型掌握的知识比表现出来的更多!

论文地址:
https://arxiv.org/pdf/2410.02707研究人员在LLM内部表示上训练分类器,以预测与生成输出的真实性相关的各种特征。
结果表明LLM的内部状态编码反映出的真实性信息,比以前认识到的要多得多。
这些真实性信息集中在特定的token中,利用这一属性可以显著提高检测LLM错误输出的能力。

虽说这种错误检测无法在数据集中泛化,但好处是,模型的内部表示可用于预测模型可能犯的错误类型,从而帮助我们制定缓解错误的策略。
研究揭示了LLM内部编码和外部行为之间的差异:可能编码了正确的答案,却生成了不正确的答案。
——简单来说就是,LLM它知道,但它不想告诉你!
LLM在装傻
作者建议将重点从以人类为中心的幻觉解释转移到以模型为中心的视角,检查模型的中间激活。
不同于使用RAG或者依赖更强大的LLM judge,本文工作的重点是仅依赖于模型输出的logits、softmax后的概率和隐藏状态的计算。
错误检测器
第一步是确定真实性信号在LLM中的编码位置。
假设我们可以访问LLM的内部状态(白盒),但不能访问任何外部资源(搜索引擎或其他LLM)。
建立一个数据集D,由N个问题标签对组成,对于每个问题,提示模型生成响应,从而得到一组预测 答案。
接下来,比较LLM生成的回答与正确答案,从而构建错误检测数据集(这一部可由AI代劳)。
实验选择了四个LLM:Mistral-7b,Mistral-7b-instruct-v0.2,Llama3-8b和Llama3-8b-instruct。

作者选取了10个跨越不同领域和任务的数据集:TriviaQA、HotpotQA(with/without context)、Natural Questions、Winobias、Winogrande、MNLI、Math、IMDB review sentiment analysis和另一个自制的电影角色数据集。
实验允许无限制地生成响应以模拟现实世界LLM的用法,并贪婪地解码答案。
性能指标
测量ROC曲线下面积以评估错误检测器,这能够反映模型在多个阈值中区分阳性和阴性情况的能力,平衡灵敏度(真阳性率)和特异性(假阳性率)。
错误检测方法
Majority:始终预测训练数据中最频繁的标签。
聚合概率/logits:从之前的研究中选取几种方法,包括计算这些值的最小值、最大值或平均值。
P(True):通过提示要求LLM评估其生成的正确性时。
Probing:在模型的中间激活上训练一个小分类器,以预测已处理文本的特征,这里使用线性探测分类器对静态token进行错误检测。
作者认为,现有方法忽略了一个关键的细节:用于错误检测token的选择。
研究者通常只关注最后生成的token或取平均值,然而,由于LLM一般会生成长格式响应,这种做法可能会错过重要的部分。
本文中,作者关注表示确切答案的token(EXACT ANSWER TOKENS),它代表了生成的响应中最有意义的部分。

这里将EXACT ANSWER TOKENS定义为,如果修改则会改变答案正确性的token。
实践中,作者使用设置好的instruct模型代劳,来提取确切答案。之后,通过简单的搜索过程确定对应的token。
重点关注4个特定token:第一个确切答案的token及其前一个token、最后一个确切答案token及其后一个token。
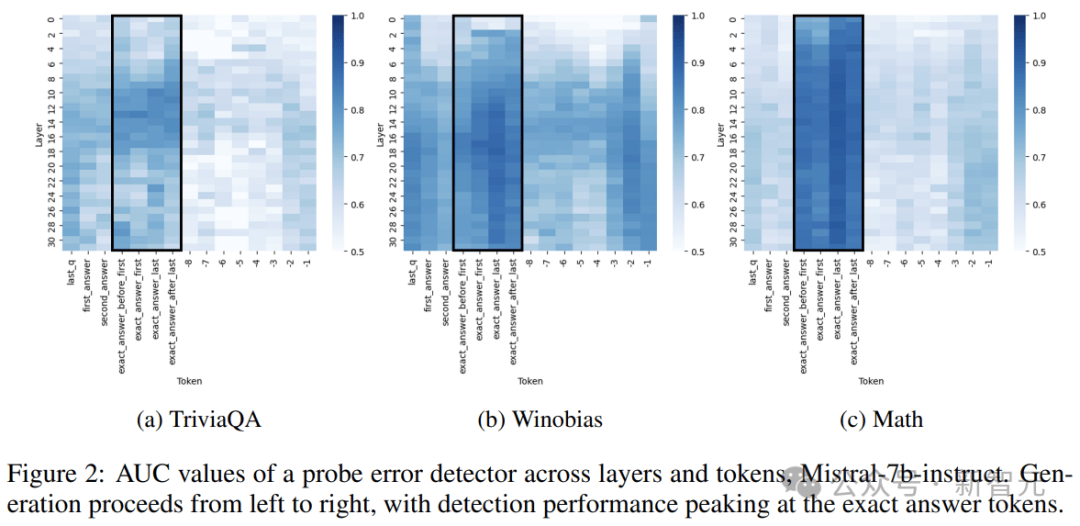
作者广泛分析了层和token选择对分类器的激活提取的影响,通过系统地探测模型的所有层,从最后一个问题token开始,一直到最终生成的token。
上图显示了Mistral-7b-Struct中各个层和token关于探测的AUC指标。虽然一些数据集似乎更容易进行错误预测,但所有数据集都表现出一致的真实性编码模式,中后期层通常会产生最有效的探测结果。

通过比较使用和不使用EXACT ANSWER TOKENS的性能,来评估各种错误检测方法,上表展示了三个代表性数据集上的AUC。
不同任务中的泛化
了解错误检测器在不同任务中的泛化能力,对于实际应用程序至关重要。
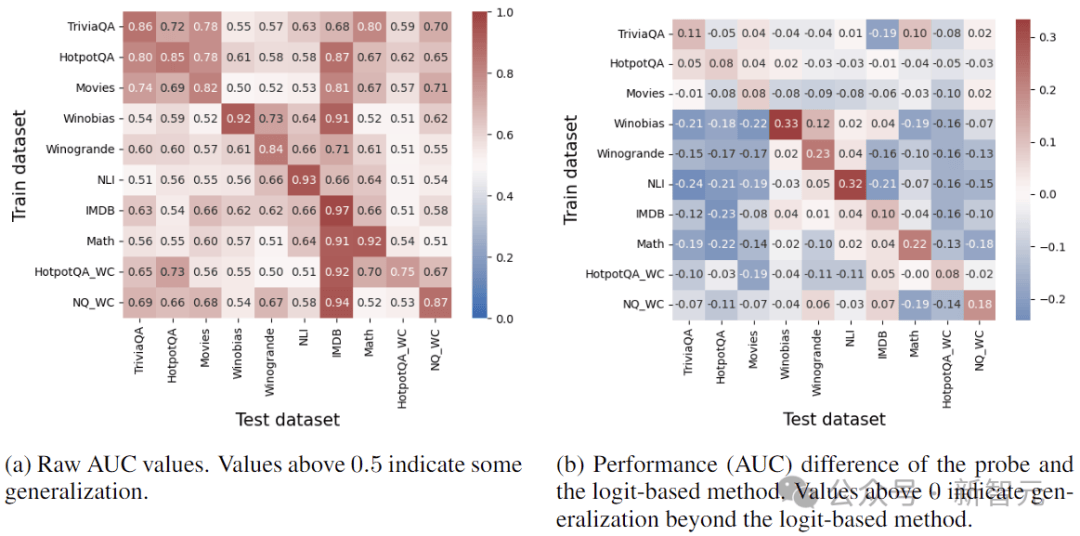
上图(a)显示了Mistral-7b-instruct的泛化结果,大于0.5的值表示泛化成功。乍一看,大多数热图值超过了0.5,似乎任务之间存在一定程度的泛化。
然而事实上,大部分性能可以通过基于logit的真度检测来实现。图(b)显示了从最强的基于Logit的基线(Logit-min-exact)中减去结果后的相同热图。
这表示检测器的泛化程度很少超过仅依赖Logit所能达到的效果。所以,泛化并不源于真实性的内部编码,而是反映了已经通过logits等外部特征访问的信息。
经过训练的探测分类器可以预测错误,但其泛化能力只发生在需要相似技能的任务(如事实检索)中。
对于涉及不同技能的任务,例如情感分析,探测分类器与基于logit的不确定性预测器效果差不多。
错误类型研究
在确定了错误检测的局限性,并研究了不同任务的错误编码有何不同之后,作者深入研究了单个任务中的错误,根据模型对重复样本的响应对其错误进行分类。
比如,持续生成的相同错误与偶尔生成的错误属于不同类别。
研究人员在T = 30的温度设置下,对数据集中的每个样本进行采样,然后分析答案的结果分布。

上图展示了三种代表性的错误类型:
图(4a)中,模型通常会给出正确的答案,但偶尔会出错,这意味着存在正确的信息,但采样可能会导致错误。
图(4b)中,模型经常犯同样的错误,但仍保留了一些知识。
图(4c)中,模型生成了大量错误的答案,整体置信度较低。
分类的标准有三个:生成的不同答案的数量,正确答案的频率,以及最常见的错误答案的频率。
上表显示了所有模型的测试集结果。结果表明,可以从贪婪解码的中间表示中预测错误类型。
检测正确答案
模型的这种内部真实性如何在响应生成过程中与其外部行为保持一致?
作者使用经过错误检测训练的探测器,从同一问题的30个响应中选择一个答案,根据所选答案衡量模型的准确性。
如果这种准确性与传统解码方法(如贪婪解码)没有显著差异,则表明LLM的真实性内部表示与其外部行为一致。
实验在TriviaQA、Winobias和Math上进行,选择probe评估的正确性概率最高的答案。这里比较了三个基线:贪婪解码;从30个候选答案中随机选择;选择生成的最频繁的答案。
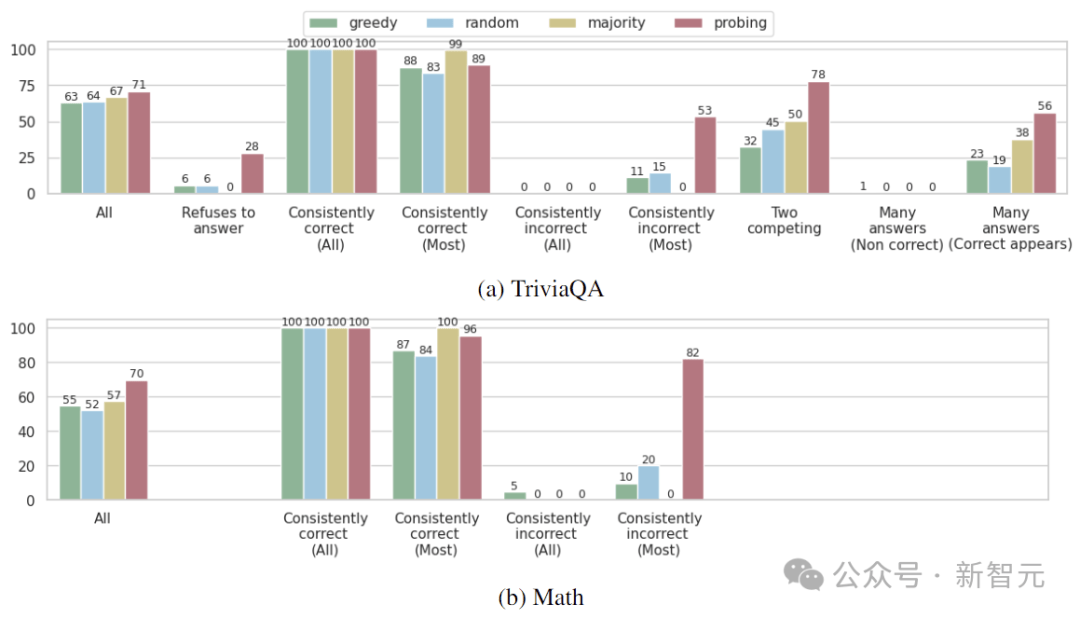
结果如上图所示,总体而言,使用探针选择答案可以提高LLM所有检查任务的准确性。但是,改进的程度因错误类型而异。

